


Discover more from Sense of Awareness
The Prime Importance
How our cells creates protein? All you wanted to know about nucleotide, codons, amino acids, the ribosome mechanism, and of course, proteins! Why should you care? SEE THE MURDER BONUS AT THE END!

Back to Basics
To understands why the current wave of gene therapies hold within them a much greater risk than we been told, including the use of codon optimization technology in these products, we first need to understand how our cells creates proteins. The word Protein is derived from the Greek word “proteios”, which means “primar” or “of prime importance”. So yes, understanding proteins is important.
It is sometimes challenging to read posts made by people who work in field of biology if you don’t have enough (or any) education on the topic. There is a lot of gaslighting being directed against people who challenge the move to gene therapies and who don’t understand the process of protein creation in the cells. While IMHO you don’t need the knowledge you are about to read to understand why codon optimization is a bad idea (hopefully my next article will be the latest summary of the topic), it does make sense to understand the way our cells create protein to have a deeper understanding of the risks related to codon optimization.
The purpose of this article is to try to provide as comprehensive understanding to the process of protein creation as needed, so not only you will understand why codon optimization is a bad idea, but also have the capacity to “play in your mind” the “how” the use of this technology lead to the risks it entails. I tried my best to explain to myself, I hope you would like it, and as always - if I made any mistake, please contact me and I’ll be happy to correct it.
Wait! Gene Therapy???
The new generation of “vaccine technologies” such as mRNA, adenovirus, and self-Amplifying RNA (saRNA) are gene therapies. According to the ASGCT, which is the American Society of Gene & Cell Therapy (which is the primary professional membership organization for gene and cell therapy), “because the vaccine introduces new genetic material into cells for a short period of time to induce antibodies, it is a gene therapy as defined by ASGCT”. This is in line with the FDA’s definition of gene therapy as “human gene therapy seeks to modify or manipulate the expression of a gene or to alter the biological properties of a living cell for therapeutic use”. Anyone who claims otherwise is lying to themselves and/or lying to you.
Nucleotide, Codons, Amino Acids
Nucleotide: A nucleotide serves as the fundamental building block of nucleic acids, specifically deoxyribonucleic acid (DNA) and ribonucleic acid (RNA). Its structure consists of three main components:
Sugar: Every nucleotide contains a pentose sugar, a five-carbon molecule. In DNA, the sugar is deoxyribose, while in RNA, it is ribose.
Nitrogenous Base: Attached to the sugar is a nitrogenous base. These bases fall into two categories: purines, characterized by larger, double-ringed structures, and pyrimidines, which are smaller and have single-ringed structures. DNA comprises four bases: adenine (A), guanine (G), cytosine (C), and thymine (T). RNA shares three of these bases (adenine, guanine, and cytosine) and replaces thymine with uracil (U).
Phosphate Group: Finally, a phosphate group is linked to the sugar molecule. This group carries a negative charge and plays a crucial role in the chemical reactions involved in nucleic acid metabolism.
Codon is a sequence of three nucleotides that serves as the basic unit of the genetic code.
Codons function as instructions for building proteins, where each codon corresponds to a specific amino acid.
There are 64 possible codons, calculated as 4 (different bases) to the power of 3 (letters). However, there are only 20 amino acids, resulting in degeneracy, meaning that multiple codons can encode the same amino acid.
Out of the 64 codons, 61 are used to encode the 20 amino acids. These amino acids include Alanine (Ala), Arginine (Arg), Asparagine (Asn), Aspartic acid (Asp), Cysteine (Cys), Glutamine (Gln), Glutamic acid (Glu), Glycine (Gly), Histidine (His), Isoleucine (Ile), Leucine (Leu), Lysine (Lys), Methionine (Met), Phenylalanine (Phe), Proline (Pro), Serine (Ser), Threonine (Thr), Tryptophan (Trp), Tyrosine (Tyr), and Valine (Val).
Stop Signals: Three codons—UAA (Ochre), UAG (Amber), and UGA (Opal) function as stop signals, indicating the end of protein synthesis.
Multiple codons amino acids: Of the 20 amino acids, 18 are encoded by two to six codons.
Single Codon amino acids: Only two amino acids, Methionine (Met) and Tryptophan (Trp), are each encoded by a single codon: AUG (which also serves as the start codon) and UGG, respectively.
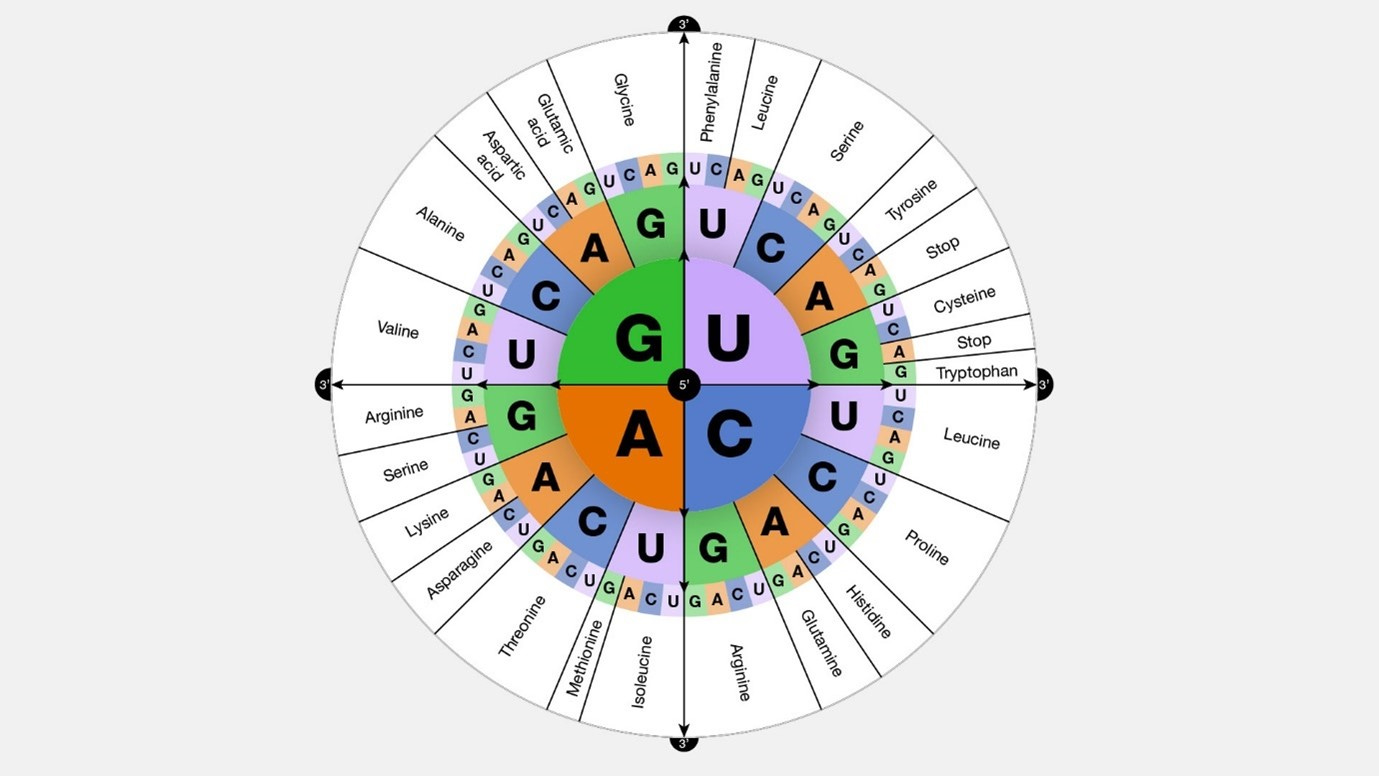
Here is a graphical representation of what was explained above:
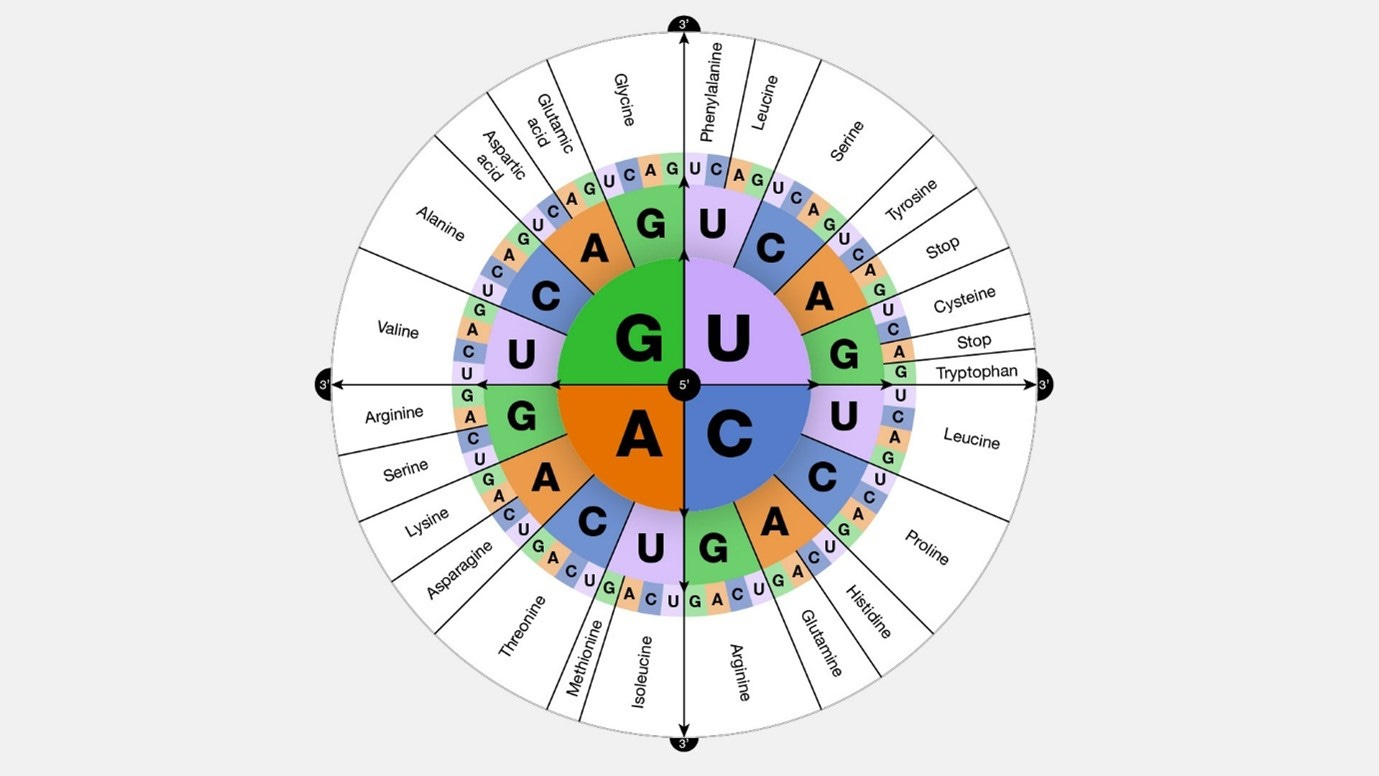
image source: gnome.gov Universality: Most organisms, ranging from bacteria to humans (with some rare exceptions among single-celled organisms), utilize the same 'standard' genetic code to translate codons in mRNA into amino acids during protein synthesis.
Mitochondria: It's worth noting that mitochondria, organelles within cells, possess their own genetic code, which exhibits slight variations from the standard code in a few codons.
Amino Acids: Each amino acid possesses a backbone structure consisting of several key elements:
Cα (alpha carbon): The central carbon atom forming the core of the amino acid backbone, connected to four other groups.
Amino Group (NH₂): This group, located at the "head" end of the amino acid opposite the side chain, contains an amine functional group with a nitrogen atom bonded to two hydrogen atoms. It participates in peptide bond formation, linking amino acids and contributing to the creation of long protein chains. It can engage in hydrogen bonding with other molecules, including water and other amino acid side chains.
Carboxyl group (COOH): Positioned at the "tail" end of the amino acid, opposite the amino group (NH₂) and the side chain (R). Connected to the Cα atom through the amide group (NH-CO) and comprise of two components:
Carbonyl Group (C=O): A carbon atom double-bonded to an oxygen atom (referred to as the carbonyl oxygen).
Hydroxyl Group (OH): Consisting of an oxygen atom bonded to a hydrogen atom and another oxygen atom, forming part of the carbonyl group.
Side chain (R): This variable group is unique to each amino acid and plays a crucial role in its properties and function.
Amide Group (NH-CO): Connects the Cα atom to the carbonyl carbon of the carboxyl group. Contains a nitrogen atom bonded to a carbonyl group (C=O) and another hydrogen atom, known as the amide hydrogen.
The Ribosome Mechanism
Proteins & the ribosome: Proteins are constructed from one or more chains of amino acids known as polypeptides. The synthesis of polypeptides within cells occurs through the utilization of cellular structures called ribosomes. Ribosomes serve as the cellular machinery responsible for protein synthesis, and multiple ribosomes are present in each cell ().
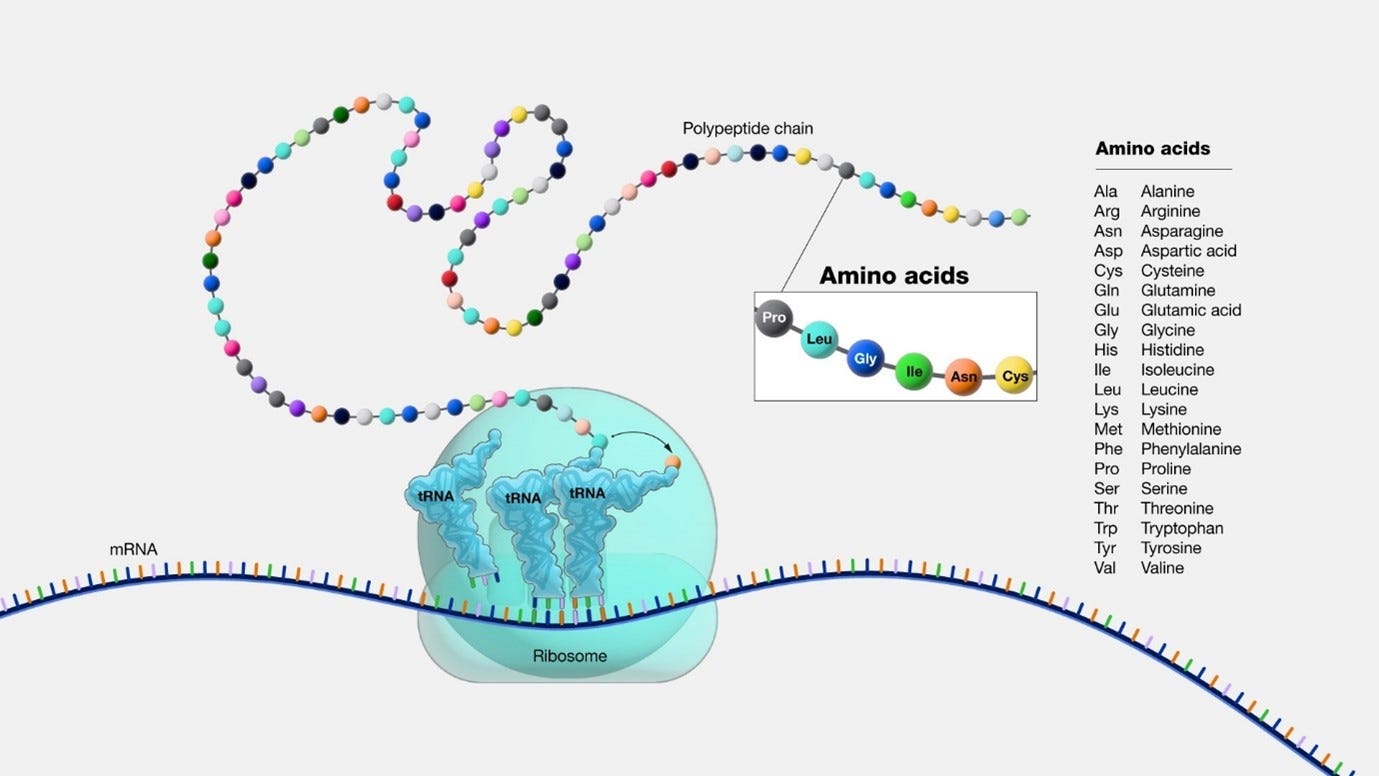
image source: gnome.gov Ribosome Operation: the way the ribosomes operate are as follows:
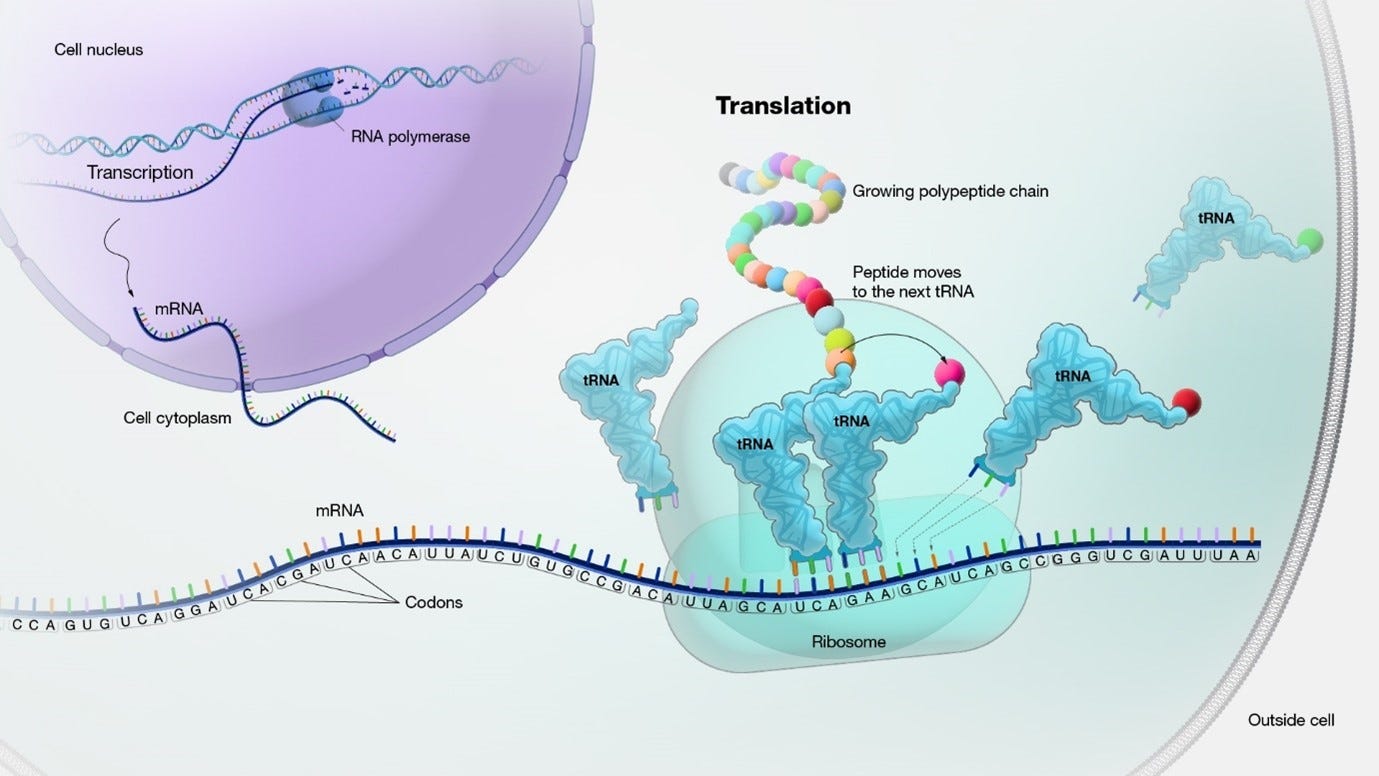
The ribosome is “processing” the mRNA sequence, which is a chain of codons. The “Translation” phase is a combination of 3 stages: initiation, elongation, and termination.
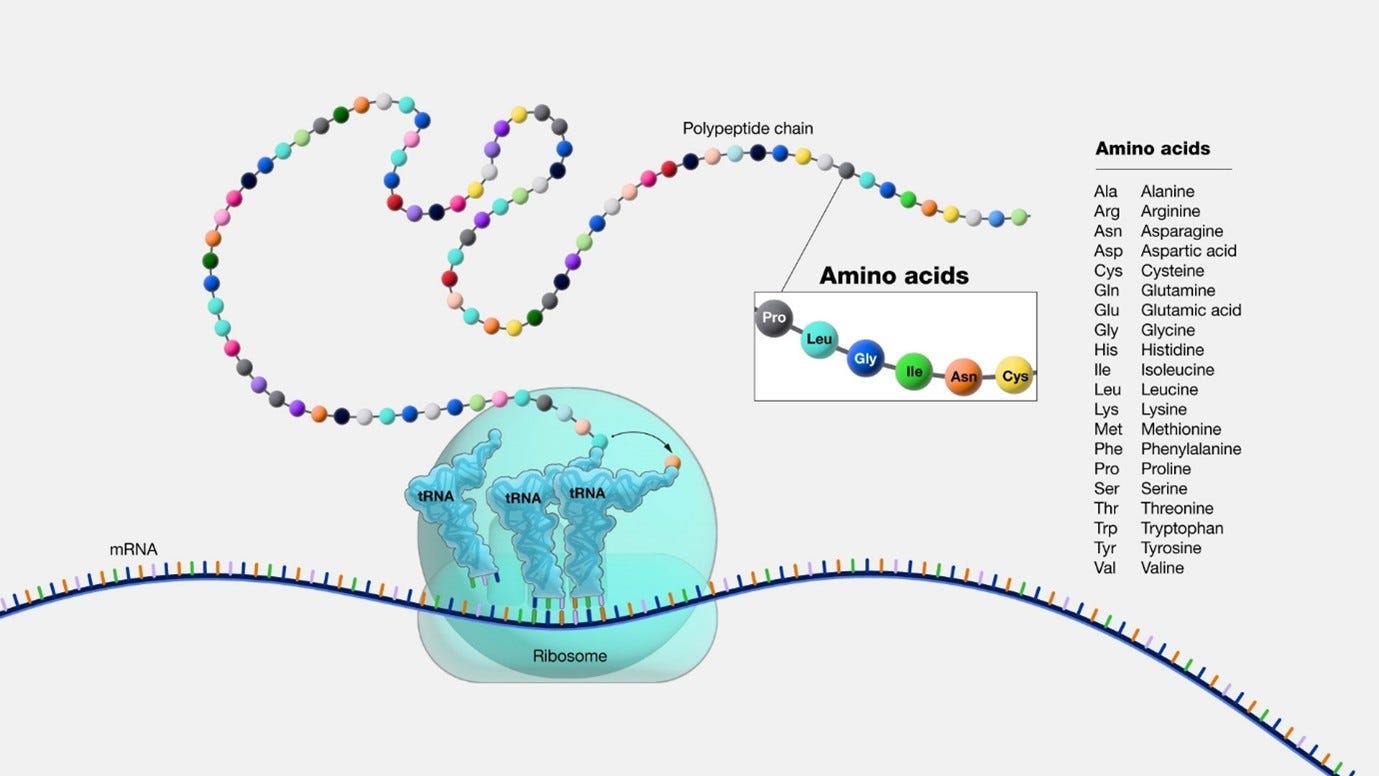
image source: genome.gov 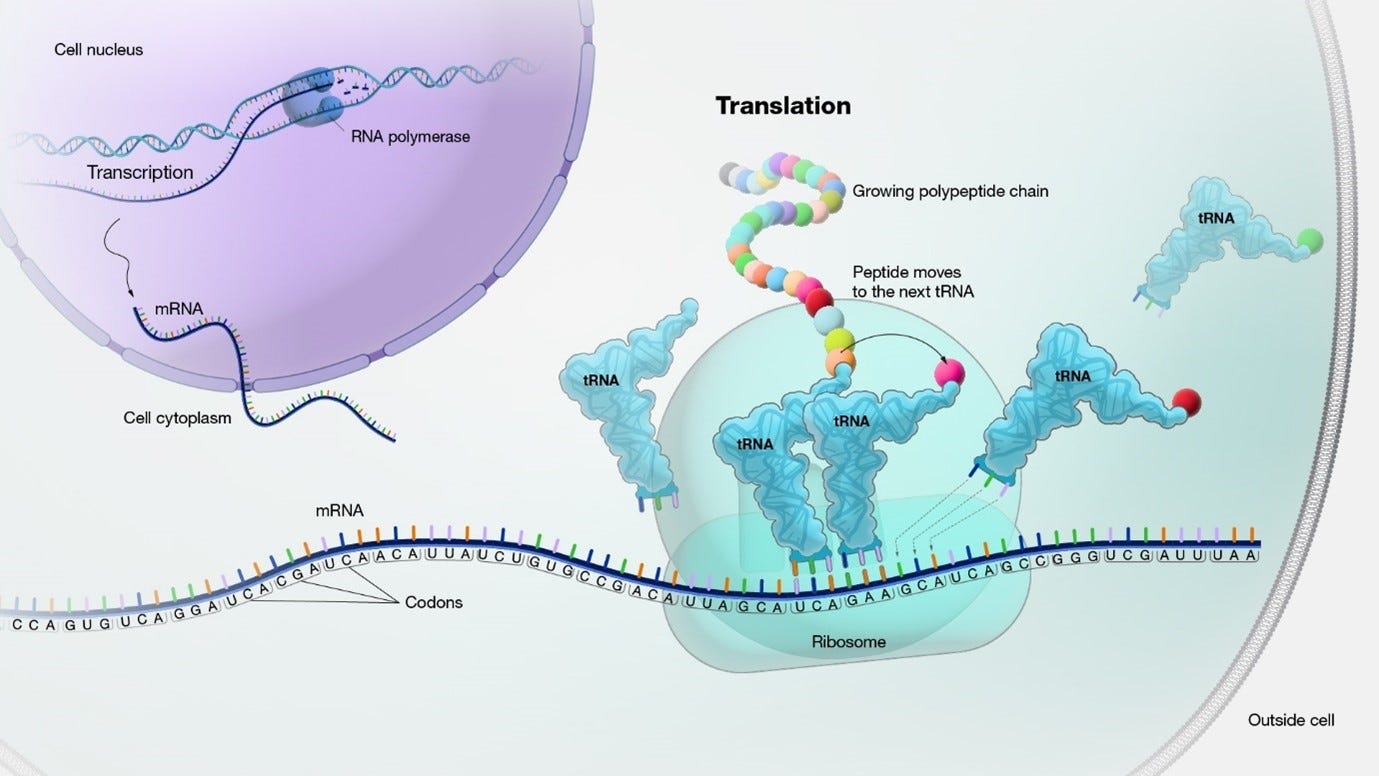
(image source: genome.gov) At first, an initiation phase occurs:
The small ribosomal subunit binds to the mRNA at the start codon (AUG).
The initiator tRNA, carrying the amino acid methionine, binds to the start codon on the mRNA. The large ribosomal subunit joins to form a functional ribosome.
the Elongation phase: Next, the ribosome moves along the mRNA in the 5' to 3' direction. The numbers 5 and 3 refer to the carbon atoms in the sugar backbone of the nucleotide subunits, where the the 5' end of the chain has a phosphate group attached to the 5th carbon, and the 3' end has a hydroxyl group attached to the 3rd carbon.
Codon recognition takes place as incoming aminoacyl-tRNAs align their anticodons with the mRNA codons.
Incoming aminoacyl tRNAs carrying the appropriate amino acids bind to the corresponding codons on the mRNA.
Peptide bonds are formed between adjacent amino acids, resulting in the growing polypeptide chain.
After the formation of each peptide bond, the ribosome advances along the mRNA, moving the tRNA carrying the growing polypeptide to the P site.
The uncharged tRNA is moved to the E site and then released from the ribosome.
Termination: The elongation phase continues until a stop codon (UAA, UAG, or UGA) is encountered on the mRNA. Release factors recognize the stop codon and promote the hydrolysis of the bond between the tRNA and the last amino acid, releasing the completed polypeptide chain.
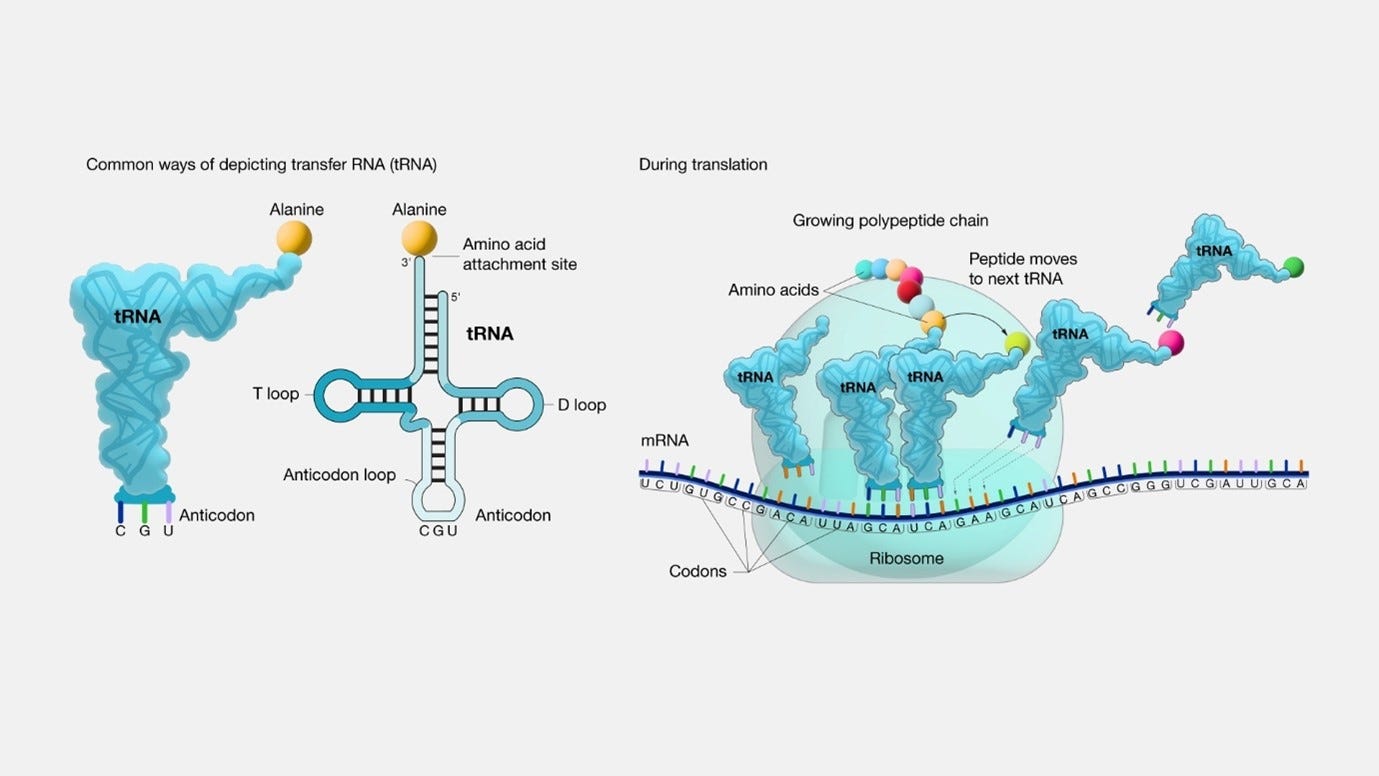
tRNA: In order to translate the mRNA sequence to a protein (or more correctly, to translate each codon to an amino acid), the cell is using tRNA, which stands for transfer RNA. “Transfer RNA serves as a link (or adaptor) between the messenger RNA (mRNA) molecule and the growing chain of amino acids that make up a protein. Each time an amino acid is added to the chain, a specific tRNA pairs with its complementary sequence on the mRNA molecule, ensuring that the appropriate amino acid is inserted into the protein being synthesized”. Each tRNA is carrying an amino acid.:
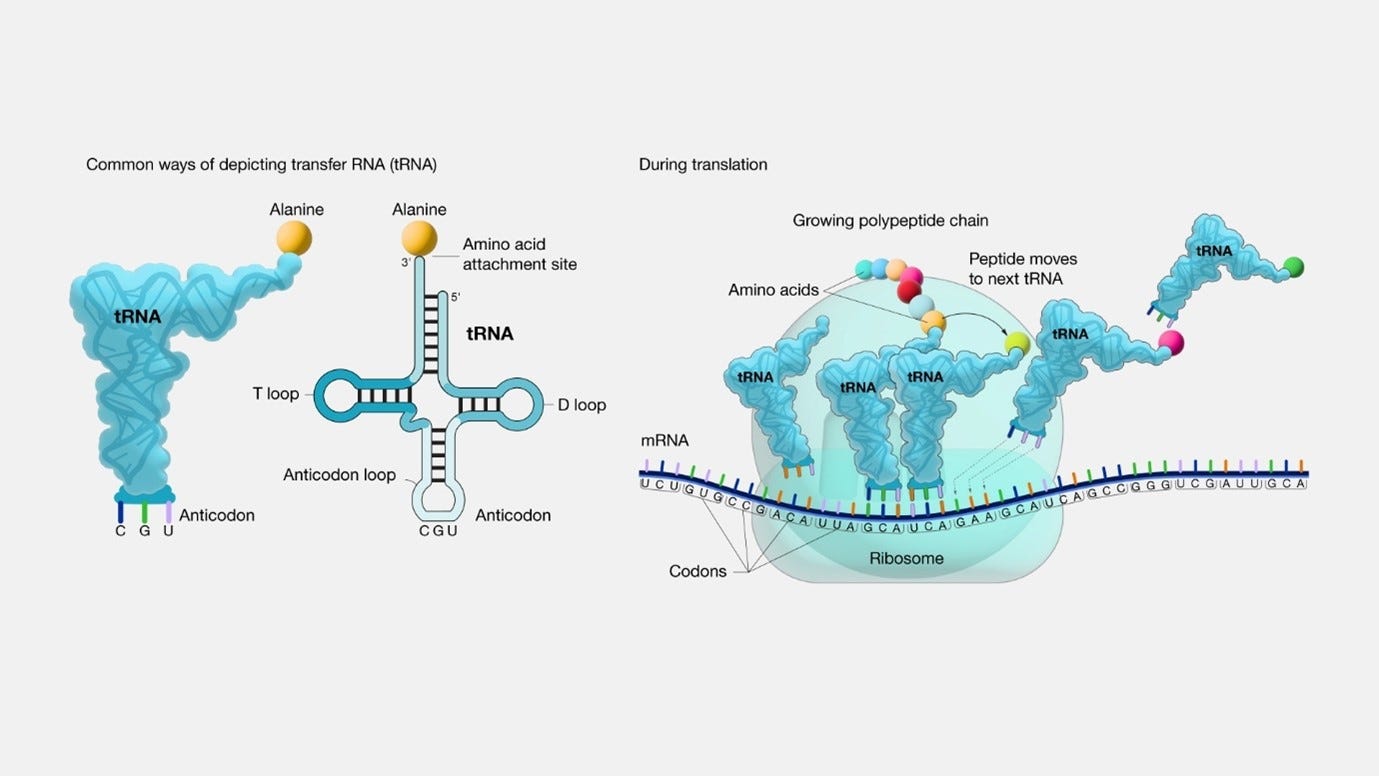
image and quote source: genome.gov tRNA & amino acids: tRNAs acquire their specific amino acids through a process known as aminoacylation, facilitated by specialized enzymes called Aminoacyl tRNA Synthetases (AARS). There are 20 different AARS. This process is fuelled by the energy derived from Adenosine Triphosphate (ATP), which is in the case of eukaryotic cells (cells that have a true nucleus enclosed within a membrane), is being provided by the mitochondria. The sequential steps in this process are as follows:
A free amino acid enters the active site of the AARS.
Simultaneously, a specific tRNA, possessing a matching anticodon sequence, binds to another site on the AARS.
The hydrolysis of ATP releases energy, which is utilized to create a covalent bond between the amino acid's carboxyl group and the 3'-hydroxyl group at the end of the tRNA molecule.
The charged tRNA, now referred to as aminoacyl-tRNA, is released from the AARS, becoming ready to actively participate in the process of protein synthesis.
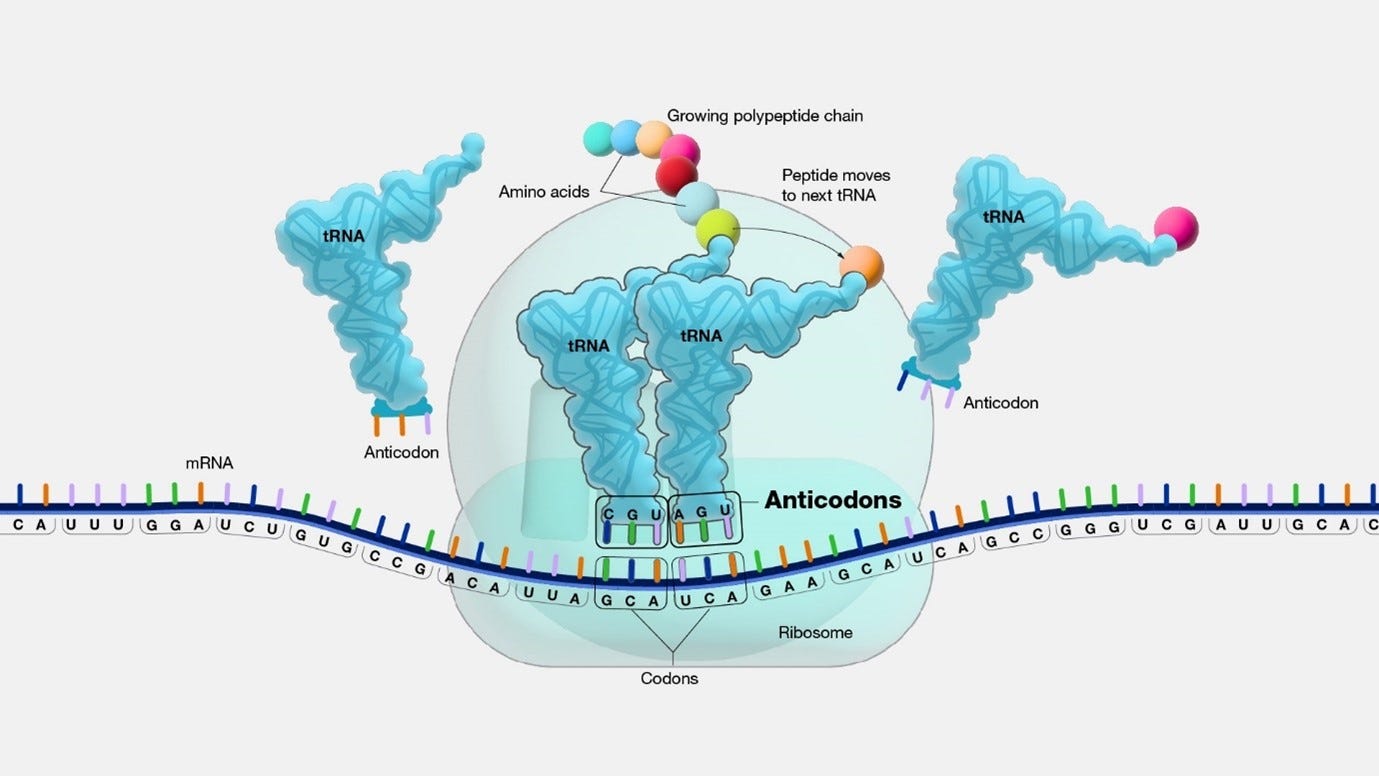
Anticodon: During the ribosome's processing of a codon, a particular tRNA is employed based on its anticodon, which is a vital component of each tRNA that plays a crucial role in protein synthesis. The anticodon is a trinucleotide sequence (sequence of three nucleotides in a nucleic acid molecule, such as DNA or RNA) situated at one end of a transfer RNA (tRNA) molecule. It pairs specifically with its complementary codon on the mRNA molecule, typically in the A-site (aminoacyl site) of the ribosome during protein synthesis.
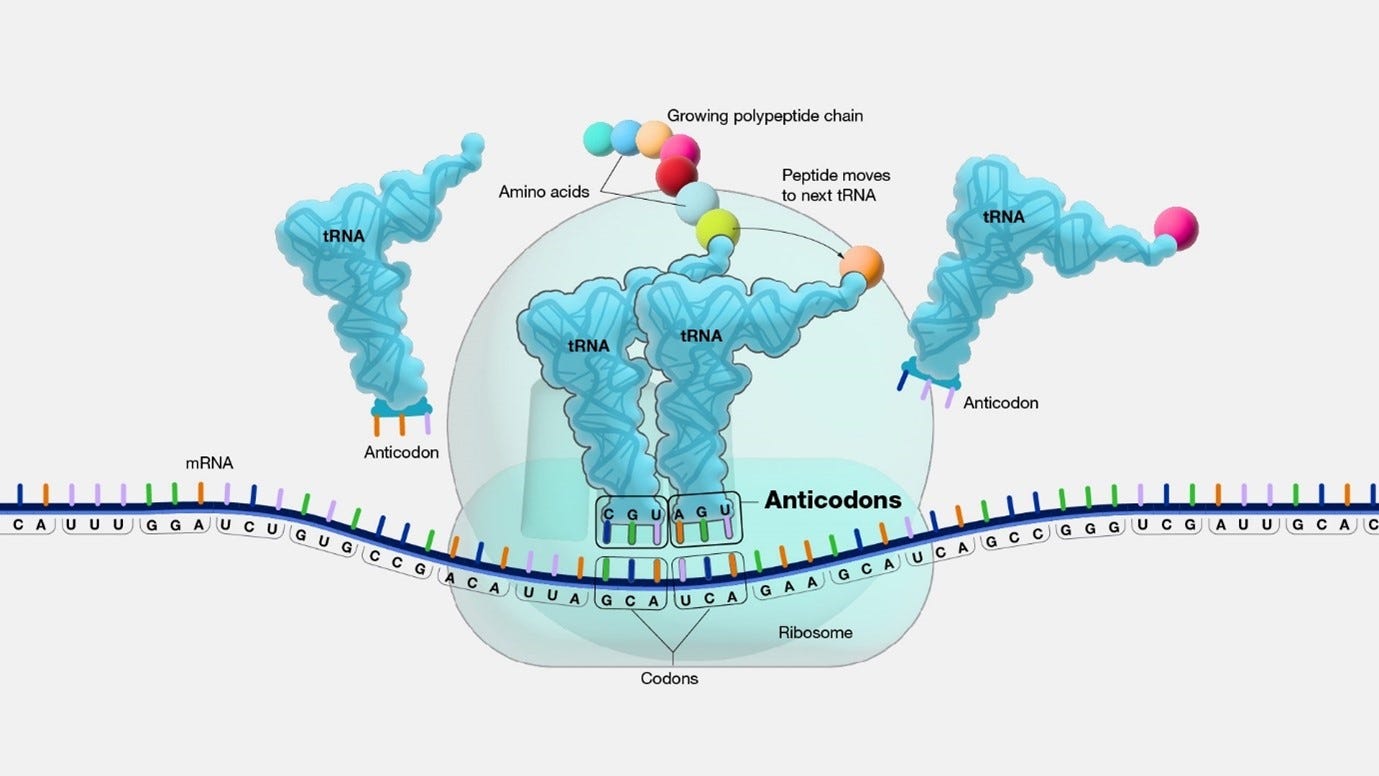
image source: genome.gov Watson-Crick base pairing: The binding mechanism responsible for the specificity in DNA and RNA is termed Watson-Crick base pairing. This pairing is driven by two fundamental elements: hydrogen bonding and geometric fit.
Hydrogen Bonding:
Between each correctly paired base, specific hydrogen bonds form between precise atoms within the bases.
These hydrogen bonds function like miniature bridges, maintaining the stability of the two strands in a DNA or RNA molecule, forming a resilient double helix structure.
Different base pairings exhibit varying numbers of hydrogen bonds, with G-C pairs forming three hydrogen bonds, and A-T/U pairs forming two hydrogen bonds. This variation contributes significantly to the overall stability and specificity of the base pairing.
Geometric Fit:
The structure of the four nitrogenous bases (adenine, guanine, cytosine, and thymine/uracil) allows for specific pairings based on their size and hydrogen bond acceptor/donor properties.
Adenine, a purine, pairs exclusively with thymine (in DNA) or uracil (in RNA), a pyrimidine, due to their complementary shapes and hydrogen bonding capabilities.
Guanine, another purine, pairs exclusively with cytosine, a pyrimidine, based on their geometries and hydrogen bonding potential.
This specific geometric fit ensures that only the correct bases can pair up, preventing mismatches that could lead to errors in DNA replication or RNA transcription.
Together, the specific geometric fit and hydrogen bonding interactions between paired bases allow for the precise and stable formation of the DNA double helix and RNA structures, which are essential for storing and transmitting genetic information with high fidelity.
Wobble: In addition to Watson-Crick base pairing, some tRNAs exhibit a unique recognition capability for multiple codons, a phenomenon known as wobble. This mechanism is primarily observed at the first (5') position of the anticodon, enhancing the efficiency of cellular operations by reducing the number of tRNAs required for each amino acid. Wobble occurs through specific interactions:
G-U wobble: Guanine in the anticodon can recognize both uracil and cytosine at the third position of the codon.
I-U/C wobble: Inosine (I), a modified guanine, can recognize uracil, cytosine, and adenine at the third position.
Other wobble pairings: Although less common, additional wobble pairings exist. However, the flexibility of wobble interactions is primarily concentrated at the first anticodon position.
This unique wobbling ability allows certain tRNAs to efficiently recognize and pair with multiple codons, contributing to the optimization of cellular processes by minimizing the diversity of tRNAs needed for each amino acid.
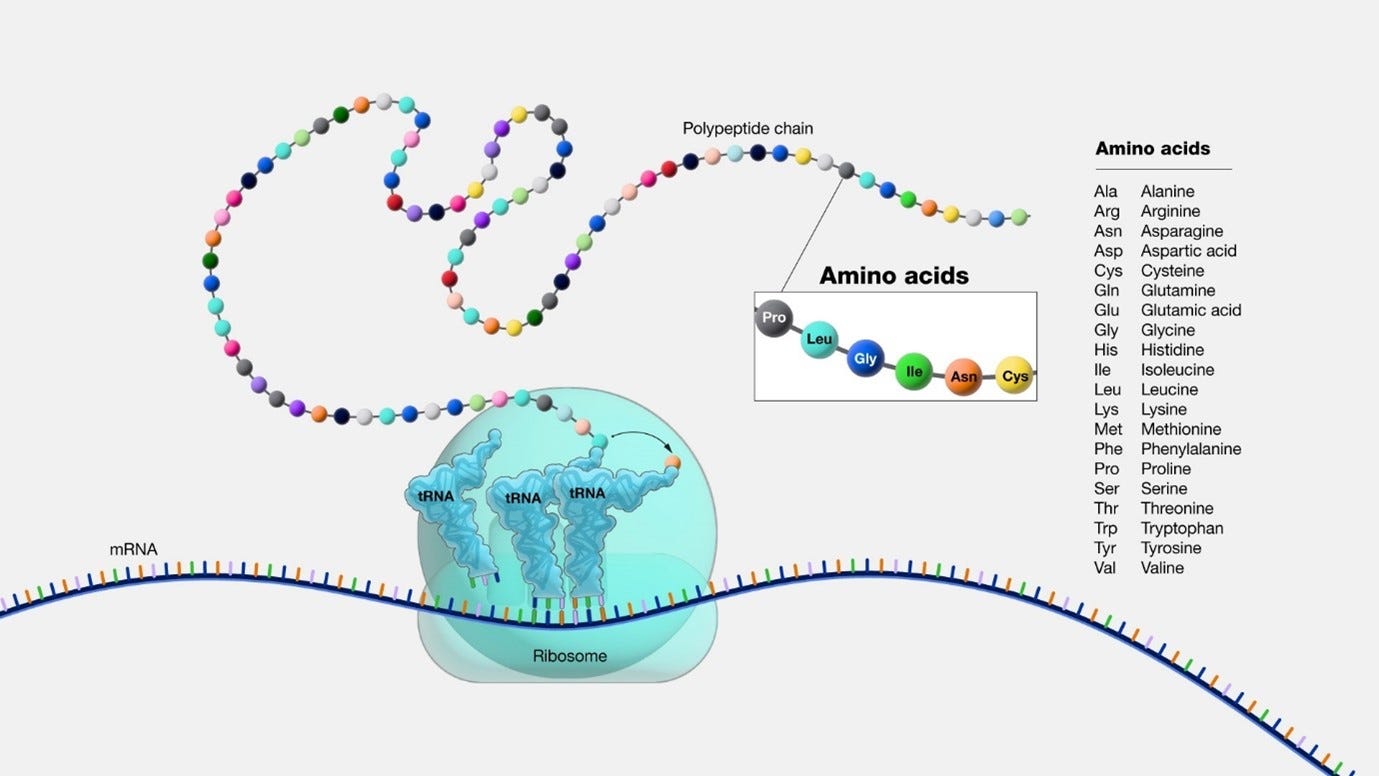
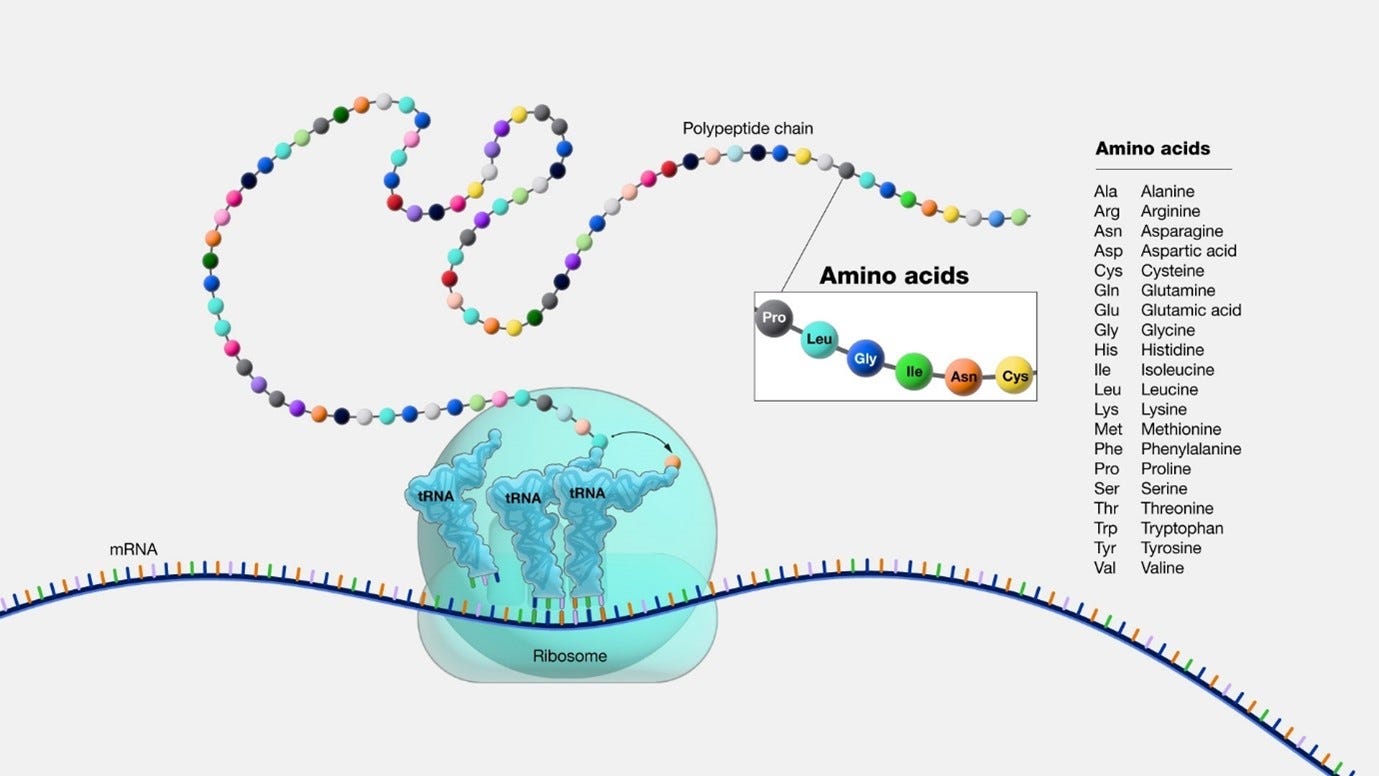
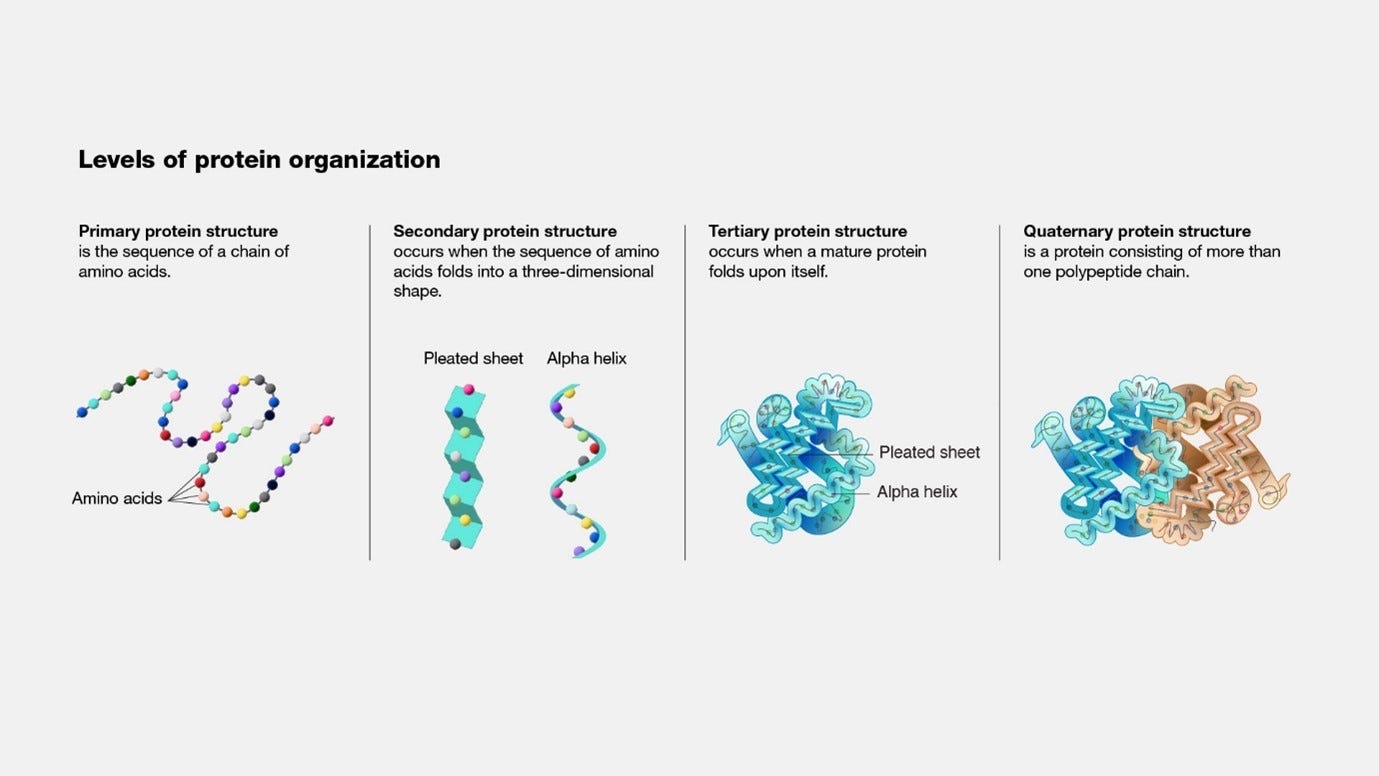
Proteins and their four structures
Proteins are made from one or more chains of amino acids called polypeptide. The protein has 4 structures.
The first structure is the primary protein structure, which you can think of as the genetic code in a sequence.
The secondary protein structure is the folding of specific segments of the protein into either a pleated sheet shape or an alpha helix shape. Both pleated sheets and alpha helices involve hydrogen bonding between the carbonyl oxygen and amide hydrogen of amino acids in the polypeptide backbone, while pleated sheets also being stabilized by ionic interactions, also known as salt bridges.
Hydrogen bonding in alpha helix:
Direction: Hydrogen bonds form within the same polypeptide chain, creating a right-handed helical (coiled) structure.
Pattern: in alpha helix there is fixed, repeating pattern (always between residues i and i+4) of hydrogen bonding, which forces the chain into a tight coil with a regular hydrogen bond network. This rigidity prevents the formation of loops and promotes the helical structure.
Number of bonds: Each amino acid residue within the helix participates in one hydrogen bond, acting as both a donor and acceptor.
In alpha helices, hydrogen bonds form between the backbone amides and carbonyls, where hydrogen bonding occurs with other residues or with water.
Hydrogen bonds in pleated sheets:
When it comes to patterns sheets, there are two types of hydrogen Bonding: Intramolecular (occurs within the same polypeptide chain) and Intermolecular (occurs between multiple polypeptide chains).
In intermolecular pleated sheets, where hydrogen bonds connect different polypeptide chains (strands) that run parallel or antiparallel to each other, the pattern of bonding can vary, and some residues might participate in multiple hydrogen bonds due to interactions with different chains.
In the Intramolecular bond, the polypeptide chain folds back on itself, which is known as hairpin motifs or β-turns. β-turn formation occurs when a carbonyl oxygen of residue (i) donates a hydrogen bond to the amide hydrogen of a residue that is not four positions ahead. It could be three positions ahead (i+3), five positions ahead (i+5), or even further depending on the specific sequence and loop conformation. Additionally, the hydrogen bond can connect residues in an upward direction, meaning the carbonyl oxygen of residue (i) donates a hydrogen bond to the amide hydrogen of a residue earlier in the chain (e.g., i-2).
Salt bridges: pleated sheets can further be stabilized by ionic interactions, also known as salt bridges, between oppositely charged side chains of amino acids in different strands. Since charged groups can attract or repel each other, strategically positioned acidic (negatively charged) and basic (positively charged) residues can form salt bridges across the strands. This creates an electrostatic attraction that adds to the overall stability of the pleated sheet structure.
Proline and folding - some amino acids, like proline, can introduce kinks in the chain, facilitating β-turn formation.
Closed imine ring: Unlike other amino acids with flexible carbon-carbon bonds, proline side chain forms a closed five-membered imine ring containing four carbon atoms and one nitrogen atom, creating a rigid structure that restricts the rotation around its nitrogen-carbon bond. This rigidness prevents proline from adopting the same planar conformation as other amino acids in the polypeptide chain.
The absence of the amide hydrogen prevents proline from participating in the hydrogen bonds that stabilize α-helices and β-sheets, forcing the chain to bend around it.
Steric clashes: The proline’s bulky ring structure creates steric clashes with neighbouring amino acids, further restricting its conformational flexibility and pushing the chain to adopt a bent conformation. Steric clashes occurs when atoms or groups of atoms within a molecule come too close together, even though they are not directly bonded. This close proximity can cause repulsive forces due to the electron clouds surrounding each atom, leading to unfavourable interactions and hindering the molecule's stability or movement.
Conformational preference (direction): Proline has a natural preference for certain backbone angles, particularly the ψ (psi) angle, which is often in the range of -60° to -90°. This specific angle favours a bend in the chain, making it ideal for initiating a β-turn.
Bulky side chains have significantly larger volumes and more complex shapes compared to smaller, simpler side chains like glycine or alanine. This can disrupt the regular structure of alpha helices, making them less favourable in certain regions. Pleated sheets can accommodate some bulky residues within their strands, but their presence may influence the overall sheet arrangement. Bulky side chain groups are:
Aromatic: Aromatic compounds are a class of organic compounds characterized by having a planar ring system with alternating double and single bonds, known as a benzene ring or aromatic ring, which often have distinctive smell.
Phenylalanine (Phe, F): Its side chain contains a large, aromatic benzene ring, contributing to significant size and steric hindrance.
Tyrosine (Tyr, Y): Similar to Phe, it has a bulky aromatic ring, but with an additional hydroxyl group that can participate in hydrogen bonding, potentially influencing its bulkiness depending on the context.
Tryptophan (Trp, W): Possesses the largest aromatic side chain with a planar indole ring system, making it quite bulky and contributing to its unique properties.
Branched-chain aliphatic: a specific type of organic compound characterized by consisting primarily of carbon and hydrogen atoms arranged in an aliphatic (non-aromatic) configuration, and having a a branched structure:
Valine (Val, V): Its side chain is branched with three methyl groups, creating a bulky structure with multiple potential steric clashes.
Leucine (Leu, L): Even bulkier than Val, featuring a branched chain with four carbon atoms and four methyl groups.
Isoleucine (Ile, I): Similar to Val but with an additional carbon atom in its branched chain, contributing to its bulkiness.
Other:
Methionine (Met, M): While containing a sulphur atom, its long, linear side chain with a terminal methyl group makes it relatively bulky compared to other amino acids.
Proline (Pro, P): Its unique cyclic structure restricts conformational flexibility and creates a rigid side chain, although it might not be classified as "large" in terms of size.
The third structure, tertiary structure is when a protein folds upon itself. This folding is driven by interactions between the side chains of amino acids, including:
Hydrophobic interactions: Nonpolar side chains cluster inside the protein, away from water.
Hydrophobic amino acids: The Out of the 20 amino acids, the following are called hydrophobic amino acids: Alanine (Ala, A), Valine (Val, V), Leucine (Leu, L), Isoleucine (Ile, I), Phenylalanine (Phe, F), Proline (Pro, P), Tryptophan (Trp, W), and Methionine (Met, M).
Hydrophobic amino acids tend to cluster in the protein interior, away from water, which favours alpha helix formation via a principle of hydrophobicity, where hydrophobic residues shielded from water. This is due to what is known as the hydrophobic effect, which arises from the inherent thermodynamic properties of water and the interactions between hydrophobic molecules and water molecules. Why?
Polarity: Water molecules are highly polar, meaning they have a positive and a negative end due to unequal sharing of electrons between oxygen and hydrogen atoms, which creates a tightly ordered and structured network.
Hydrophobic molecules, like those with hydrocarbon side chains found in many amino acids, lack charged groups or polar atoms.
Hydrophobic amino acids are clustered together inside a protein, they are shielded from contact with water, eliminating the energy penalty associated with disrupting the water network. This minimizes the total free energy of the system, making it the most stable and energetically favourable configuration.
The clustering of hydrophobic amino acids also increases entropy within the protein interior, contributing to its stability.
Hydrogen bonds: Hydrogen bonds can form between side chains or between side chains and backbone atoms.
Ionic interactions: the same salt bridges that occurs in segments can occur both intramolecular and intermolecular level. While the salt bridges in the secondary structure stabilizes local folding, the salt bridges in the tertiary structure stabilizes the global conformation and function. While in secondary structure carbonyl oxygen and amide hydrogen are involved, in the tertiary structure oppositely charged side chains are involved.
Disulfide bridges or bonds: Covalent bonds between cysteine residues, creating rigidity and stability. Cysteine residues are a specific type of amino acid found in proteins. They are unique because they contain a sulfhydryl group (-SH), also known as a thiol group, on their side chain. While cysteine residues are present in all proteins, their abundance varies depending on the protein. Disulfide bonds formed when the sulfur atoms of two thiol groups share two electrons, creating a strong covalent bond. It can occur within a single polypeptide chain (intrachain) or between different polypeptide chains (interchain). It plays a critical role in protein folding and stability by:
Forming cross-links that hold different parts of the protein together.
Contributing to the overall rigidity and structure of the protein.
Influencing the protein's activity by regulating protein conformation.
The fourth structure, the quaternary structure, is when a protein is consisted of more than one polypeptide chain.
The following image (source: genome.gov) provides a graphical display the different levels of protein organization
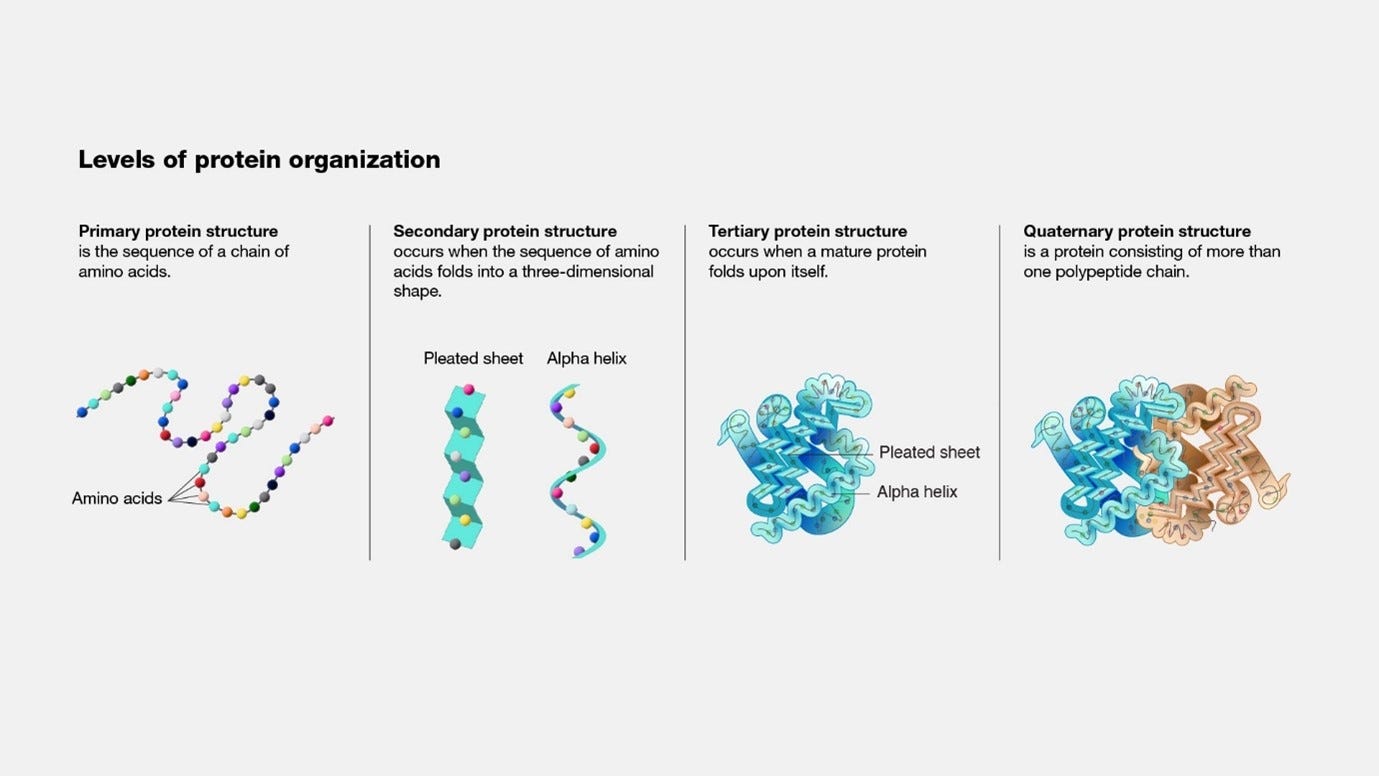
Folding: after the polypeptide chain is created and released (via the processing of the stop codons), the polypeptide chain begins to fold spontaneously into its specific three-dimensional structure. It is driven by the following factors:
The intrinsic properties of the amino acids: Their size, charge, and hydrophobicity influence how they interact with each other.
Hydrogen bonds: These bonds form between polar groups within the chain, creating local structures like α-helices and β-sheets.
Disulfide bonds: These covalent bonds between cysteine residues (amino acids) stabilize protein structure.
Interactions with other molecules: Sometimes, proteins fold with the help of chaperone proteins or other molecules.
Cleavage (clipping/cutting): Finally, there are different mechanism in the cell that can lead a polypeptide chain to be cleaved.
Enzymatic Cleavage: Specific enzymes called proteases recognize specific amino acid sequences or structural features within the polypeptide chain and cut it at those locations.
Chemical Cleavage: Certain chemicals (such as acids, bases and specific reagents) can be used to cleave peptide bonds, although this method is less common in biological systems due to its lack of specificity.
Autolytic Cleavage: Some proteins have built-in mechanisms for self-cleavage at specific sites. This can be triggered by various factors such as changes in pH, temperature, or the presence of specific molecules.
Ribozyme-mediated cleavage: Ribozymes (NOT ribosomes!!!) are RNA molecules that can act as enzymes and cleave specific sequences in RNA or DNA. Some ribozymes can also cleave peptide bonds in polypeptides.
Protein Folding Helpers: The cell has special mechanisms to help protein shape the way they should, called molecular chaperones. These are a diverse group of proteins that play essential roles in protein folding, assembly, transport, and degradation within cells. They assist other proteins, known as “client proteins”, in achieving their correct three-dimensional structures and maintaining their functional conformations. Molecular chaperones are often referred to as "protein folding helpers" or "protein quality control machinery" because of their ability to prevent misfolding, aggregation, and the formation of non-functional protein conformations. Molecular chaperones use ATP to perform their actions. These proteins do the following:
Assist in folding: these proteins bind to unfolded or partially folded proteins, providing a conducive environment for them to fold correctly and preventing misfolding or aggregation.
Prevent protein aggregation: prevent the aggregation of unfolded or misfolded proteins by binding to exposed hydrophobic regions of unfolded or misfolded proteins, shielding them from interactions with other proteins and preventing aggregation.
Assist in protein transport: aid in the transport of proteins within cells and across cellular membranes, which in this case they help the client proteins cross across cellular membranes by facilitating their unfolding and refolding during the transport process.
Regulate protein quality control: participate in cellular quality control mechanisms by identifying and targeting misfolded or damaged proteins for degradation, helping the cell to maintain protein homeostasis and prevents the accumulation of dysfunctional proteins within the cell.
Congratulations!!!
If you managed to reach this point without having your head exploded, then congratulations, you now hold a basic understanding of the way proteins are being created in your cells, and why are they created in the way they are. What might seem to be trivial to people who work in the field is not so trivial to many people, but this knowledge will allow you to better understand the insanity of delivering mRNA into your body.
WHY (THE MURDER BOBUS)
Now that you reached this far, I’ll give you one example that has nothing to do with codon optimization, on how the “vaccines” were nothing short of a murder attempt.
As described above in the section “The Ribosome Mechanism”, section e, the cell is using tRNA so that the ribosome could translate the mRNA sequence to a protein (or more correctly, to translate each codon to an amino acid). In section f, it was explained that the tRNAs acquire their specific amino acids through a process known as aminoacylation, facilitated by specialized enzymes called Aminoacyl tRNA Synthetases (AARS), and that the process is fuelled by the energy derived from Adenosine Triphosphate (ATP), which is being created by the mitochondria.
In “SARS-CoV-2 Causes Mitochondrial Dysfunction and Mitophagy Impairment” (Shang et al, 2021), the researchers “detected mitochondrial dysfunction caused by SARS-CoV-2 infection, including mitochondrial membrane depolarization, mitochondrial permeability transition pore opening and increased ROS release”. Excessive ROS production, often termed oxidative stress, can cause damage to cellular components such as lipids, proteins, and DNA, can lead to inflammation, and can trigger apoptosis (programmed cell death).
Since the impairment of the mitochondria cells within a human cell could lead to decreased ATP production and can impact the cell to handle the misfolded aggregated proteins, because the lack of ATP will lead to a higher likelihood of errors during protein synthesis, where incorrect amino acids may be incorporated into the growing polypeptide chain, leading to misfolded or dysfunctional proteins, which can lead to forming aggregates of these protein within the cell.
Without ATP, the molecular chaperones cannot perform their job, meaning that they can’t fold the spike protein correctly, cannot prevent protein aggregation, can’t assist in the transport of the spike outside the cell, and cannot regulate the protein quality control process.
Protein aggregates are associated with various diseases, including neurodegenerative disorders such as Alzheimer's and Parkinson's disease. In the case of the heart, aggregates can lead to cardiomyopathy (disease of the heart), heart failure, including heart attacks. They can also lead to cancer.
The mitochondria have an important role in handling interactions of amyloidogenic proteins (proteins that have a tendency to misfold and clump together) via the mitochondrial protein import machinery in aging-related neurodegenerative diseases. You can read more about it in “Interactions of amyloidogenic proteins with mitochondrial protein import machinery in aging-related neurodegenerative diseases”, Reed et al, 2023.
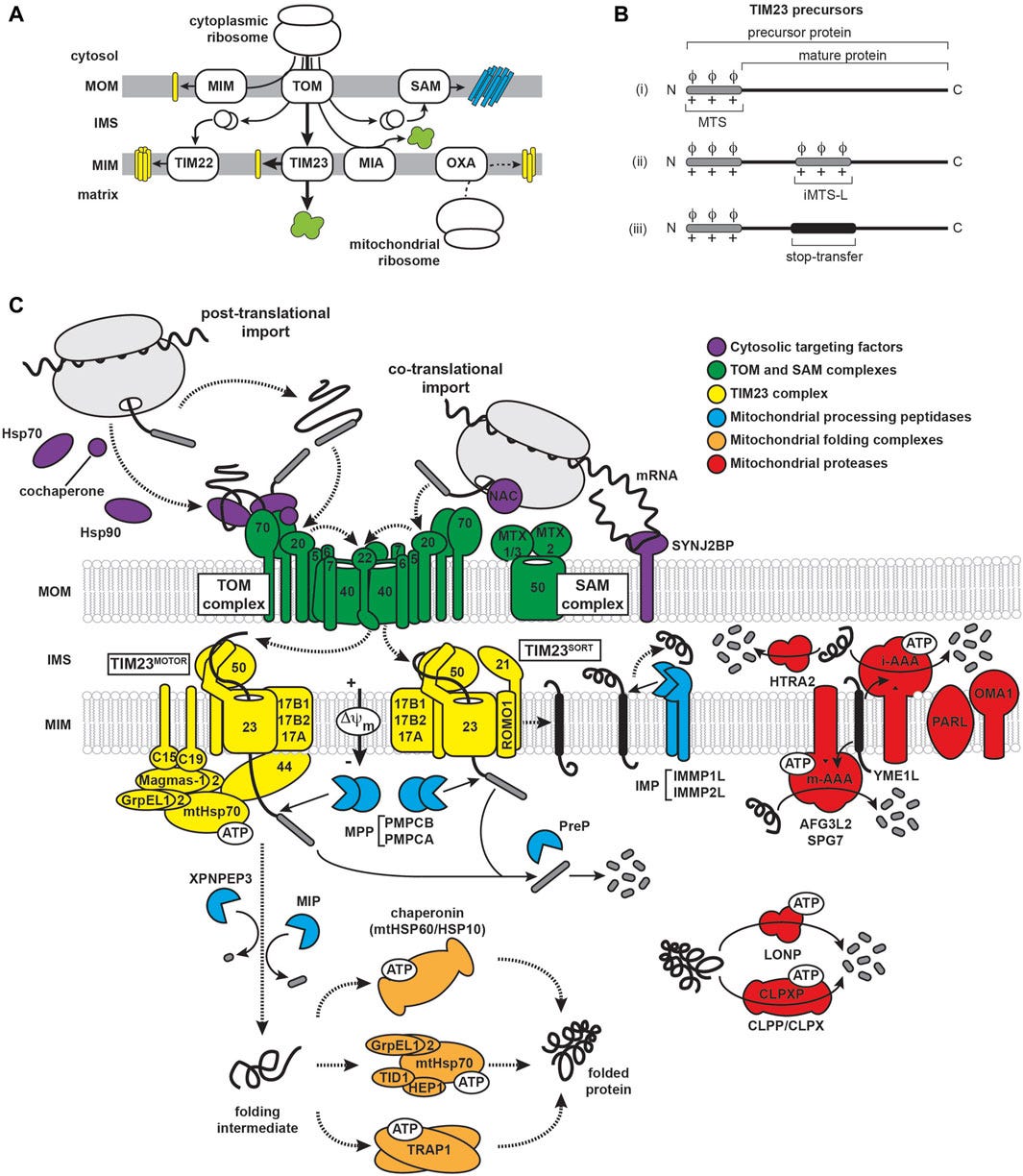
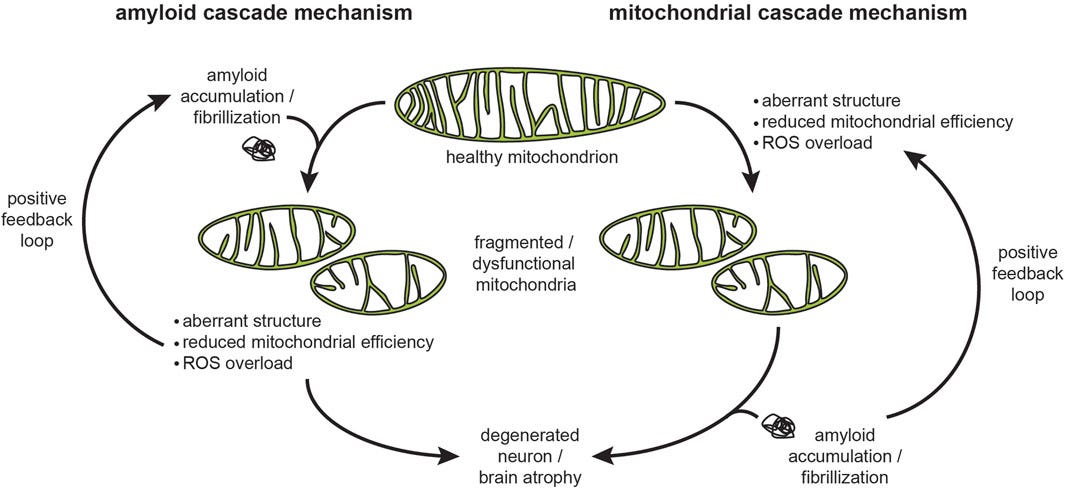
Another article (“Metabolic regulation of misfolded protein import into mitochondria”, Wang et al, 2023) also describes how “the Mitochondria also facilitate proteostasis … whereby cytosolic misfolded proteins (MPs) are imported into and degraded inside mitochondria.”
ADDENDUM - Bell’s palsy: "The activity of sodium channels and reversal of the sodium-calcium exchanger can thus contribute to the axonal degeneration of peripheral axons AFTER MITOCHONDRIA DYSFUNCTION and consequentially impaired activity of Na/K-ATPase. These processes of intra-axonal degeneration drive the sudden onset of BP (Bell’s palsy) and also explain the lack of a pronounced immune response in these models. ("The etiology of Bell’s palsy: a review", Zhang et al)
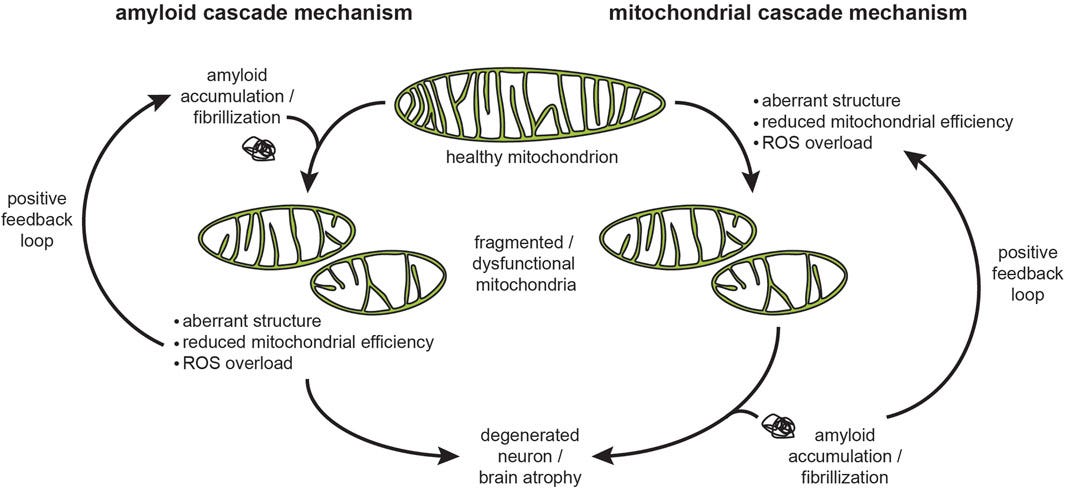
Based on the knowledge you gained by reading this article I hope you can now understand the facts I’ve mentioned in this “bonus” section. The spike proteins created in one’s cell is causing damage to the mitochondria cells, which leads to the creation of misfolded proteins and their aggregates, which the cell is unable to handle, which lead to multiple diseases.
The decision to create a product that generates proteins which targets the mitochondria cells in one’s body is nothing short of an attempt to murder people. For me, that is simply pure evil, and the only way to defeat evil is by serving the truth with love.
With love,
Ehden











Fundamentally an attempt to destroy human life at the metabolic level.
You can also throw ER Stress into the mix here, I think:
https://pubmed.ncbi.nlm.nih.gov/17670839/
https://pubmed.ncbi.nlm.nih.gov/18039139/
https://pubmed.ncbi.nlm.nih.gov/28630146/
https://pubmed.ncbi.nlm.nih.gov/33484951/