The CDC’s Vaccine Safety Datalink (VSD)
Everything you wanted to know about the CDC system but had no one to ask! (FINAL EDITION)

By Ehden Biber
Introduction
The CDC’s Vaccine Safety Datalink system has been the at the center of attention recently. Aaron Siri recently announced that lawsuit his firm just filed against the CDC on behalf of the Informed Consent Action Network (ICAN) to make public the data in the Vaccine Safety Datalink.
The purpose of this article is to educate people about VSD: Why was it created, past and current structure, the distributed data model it uses and the way data is accessed, the limitations of the system, the data ownership and privacy regulations that define possible data usage, the federal funding it received and being receiving to operate it, the ethical oversight and regulatory compliance process it followed, and more.
VSD History
Vaccine safety monitoring in the U.S. began in the late 1970s with the Monitoring System for Adverse Events Following Immunizations (MSAEFI), established by the CDC in 1978. MSAEFI collected adverse event reports from parents or guardians of children receiving publicly funded vaccines until it was replaced in 1990. The National Childhood Vaccine Injury Act (NCVIA) of 1986 paved the way for the Vaccine Adverse Event Reporting System (VAERS), co-managed by the CDC and FDA. VAERS, operational since 1990, accepts reports from diverse sources—including healthcare providers, vaccine manufacturers, and the public—to detect potential safety issues. However, its voluntary nature leads to limitations such as underreporting and incomplete data. Additionally, VAERS cannot establish whether a vaccine caused an adverse event or calculate risk rates due to the lack of denominator data and unvaccinated comparison groups.
To improve vaccine safety monitoring and overcome the shortcomings of VAERS, the CDC launched the Vaccine Safety Datalink (VSD) in 1990. This system conducts post-marketing safety assessments within specific populations. Partnering with major healthcare organizations, VSD performs population-based monitoring and research to address key immunization safety concerns. By supplying scientific data to healthcare providers, public health officials, and policymakers, VSD supports informed national immunization policies and ensures the public has access to timely, reliable safety information.
VSD focused its initial efforts on examining potential associations between immunizations and serious neurological, allergic, haematological, infectious, inflammatory and metabolic conditions, and then it was used to test new ad hoc vaccine safety hypotheses in addition to planned vaccine safety studies. The Vaccine Safety Datalink (VSD) conducts research to evaluate vaccine safety by testing hypotheses about adverse events and identifying safety signals through near real-time monitoring. To support these efforts, participating sites must meet specific requirements:
Maintain Comprehensive Digital Records: Sites need to keep computerized databases that document healthcare encounters, including detailed immunization registries with information on vaccines administered.
Access Detailed Medical Data: They must have the ability to retrieve written or electronic medical records and other data sources to provide in-depth details about specific healthcare visits.
Offer Full-Spectrum Healthcare Services: Sites are required to provide integrated healthcare services, ensuring they can track the entire range of patient care, from outpatient and emergency department visits to hospitalizations.
In addition, each site must employ specialists with expertise in vaccine safety, statistical analysis, and data management to ensure the quality and reliability of the research conducted within the VSD network.
VSD Data Model
Original design (up to 2001):
The original data model of VSD initially only obtained data for infants and kids up to the age of 6, and later expanded to adolescence and adults and by 2000 covered 6 million people, or 2% of US population.
Vaccination data were derived from computerized immunization tracking systems maintained by each MCO.
For medical encounters, each MCO maintained computerized databases on all hospital discharges and emergency room visits. Diagnoses from outpatient clinic encounters were available from some of the MCOs for certain years.
Automated pharmacy and laboratory data on, for example, seizure medications and anticonvulsant blood levels, provide valuable cross-references for identifying diagnoses that may have been related to immunization but were miscoded or overlooked.
Records of diagnostic procedures, e.g. electroencephalography and radiography, were kept, and these provided another source for establishing the presence of such conditions.
Paper medical records were often abstracted to confirm diagnoses and vaccination histories.
Patients or their parents were occasionally interviewed to obtain additional information.
Each MCO site encoded its patients’ clinical data with unique study identifiers before sending data to CDC annually for merging and analysis, thereby preserving patient confidentiality.
Refinement of study methods and the prioritization of research projects took place during monthly conference calls and annual meetings.
Limitations of the Original VSD Design (Until 2001)
The original design of the VSD, used until 2001, was characterized by a centralized data collection model. Below is a detailed breakdown of its limitations, derived from research and historical documentation:
Centralized Data Collection: Health plans were required to send de-identified data files to the CDC on an annual basis. This process resulted in static datasets that were at least six months old by the time they were available for analysis. The delay in data availability was a significant barrier to timely vaccine safety monitoring, especially for new vaccines or emerging safety concerns.
Timeliness Issues: The annual update cycle meant that the data was not current, which hindered the ability to conduct rapid analyses. For instance, studying adverse events shortly after vaccine administration was challenging, as the data lag could miss critical safety signals in near real-time.
Inefficiency in Data Access for Multi-Year Studies: For research spanning multiple years, researchers had to compile and analyze data from several annual cycle files. This process was cumbersome and time-consuming. Moreover, accessing detailed data, such as specific diagnoses or lab results, often required reviewing patient charts, which was labor-intensive and limited the efficiency of large-scale studies.
Current Design (from 2001)

The current design of the CDC's Vaccine Safety Datalink (VSD) relies on a Distributed Data Model (DDM), a decentralized approach that enhances data privacy, control, and timeliness compared to the previous centralized model. In the earlier design, health plans sent large annual data files to the CDC, which led to delays and inefficiencies. Under the DDM, participating health plans—referred to as Health Maintenance Organizations (HMOs) or Managed Care Organizations (MCOs)—assemble and maintain their data files on their own secure servers, retaining full ownership and control. This eliminates the need for extensive data transfers to the CDC and supports more frequent updates, strengthening the VSD's ability to monitor vaccine safety effectively.
Data is NOT being sent to the CDC. The CDC is using different statistical queries on the data to try and derive meaning from it. You can read about the different methods in the section “VSD Data Query Methods” below.
Data Sources and the Role of Chart Review
The VSD integrates multiple data sources to support its studies:
Automated Data: Includes electronic records from immunization databases, outpatient clinic visits, emergency department (ED) visits, and hospitalizations, maintained by all VSD sites.
Additional Sources: Medical chart reviews, patient surveys, and interviews supplement automated data.
Chart review plays a critical role in validating diagnostic codes from automated data. For example:
Conditions like narcolepsy have a low positive predictive value (PPV), meaning electronic codes alone may not reliably identify true cases.
In contrast, intussusception has a high PPV, indicating greater accuracy in automated coding.
Beyond validation, chart reviews provide essential clinical details and risk factors, enriching the data for specific health outcomes.
Standardized Data Files and Confidentiality Measures
Each VSD site prepares standardized data files containing individual-level information, such as:
Demographics
Health plan enrollment
Birth information
Vaccination records
Healthcare utilization (e.g., hospitalizations, outpatient visits, ED visits, urgent care)
A standardized data dictionary ensures consistency across sites, facilitating data integration. To protect confidentiality:
Each site retains its own data, avoiding centralized storage.
Individuals receive unique, randomized VSD identification numbers linked to their health plan IDs. This link is used solely for data collection and is otherwise inaccessible.
VSD identification numbers enable secure linkage across databases without compromising privacy.
Here is the data record structure:

Key Features of the Distributed Data Model (DDM)
Local Data Management: Each health plan stores its data on its own secure server, reducing privacy risks and allowing sites to manage data according to their own security protocols.
Dynamic Data Files (DDFs): The DDM enables the creation of dynamic data files that can be refreshed weekly, monthly, or quarterly. This shortens the gap between vaccine administration and data availability, addressing a key limitation of the centralized model.
Efficiency Gains: By removing the need to compile and send large annual files, the DDM reduces the workload on health plans and streamlines data-sharing processes.
Secure Data Transfer Methods
Data required for VSD studies are transferred between the CDC and health plans using two secure methods: the indirect method and the direct method. Both approaches protect sensitive information while enabling efficient analysis.
Indirect Method:
CDC researchers send SAS programs (written using SAS software from SAS Institute, Inc., Cary, NC) to a secure server called the "hub."
Health plans retrieve these programs at scheduled intervals, run them on their local data, and return SAS logs, output, and analytical data subsets to the hub.
Privacy is maintained as each health plan can only access its own programs and data, with no visibility into other organizations' information.
CDC researchers then retrieve the results from the hub.
Direct Method:
CDC researchers submit SAS programs interactively via a secure SAS remote session using SAS Connect, an Internet communication protocol.
SAS macros simplify data access and retrieval of logs and output.
All transfers are encrypted to ensure security.
These methods allow the CDC to analyze data without directly handling health plans' raw datasets, further safeguarding privacy.
Enhanced Capabilities Enabled by the DDM
The DDM not only improves data management but also supports advanced functionalities critical to vaccine safety research:
Rapid Cycle Analysis (RCA): Introduced in 2005, RCA leverages the DDM to provide near realtime safety surveillance. It monitors newly licensed vaccines (for two years) and seasonal influenza vaccines, complementing passive systems like the Vaccine Adverse Event Reporting System (VAERS) with systematic, data-driven insights.
Collaboration and Scalability: The DDM facilitates collaboration among health plans and the CDC, incorporating diverse data sources. The VSD has expanded to 13 sites in recent years, enhancing the representativeness and robustness of its studies. This model has also influenced networks like the Health Care Systems Research Network (HCSRN).
Reduced Curation Effort: By minimizing centralized data obfuscation, the DDM lowers barriers to participation, enabling more organizations to contribute to research.
Specialized Research: The model’s flexibility supports adaptations, such as algorithms to identify pregnant women and link medical records, broadening its application to areas like vaccine safety during pregnancy.
VSD Data Query Methods
The Vaccine Safety Datalink (VSD) utilizes a set of statistical methods to monitor vaccine safety and detect potential adverse events through its rapid cycle analysis (RCA), enabling near real-time surveillance. The primary methodologies are the Maximized Sequential Probability Ratio Test (MaxSPRT and CMaxSPRT), group sequential analysis, and TreeScan. Below is a summary of their principles, strengths, and limitations.
Maximized Sequential Probability Ratio Test (MaxSPRT and CMaxSPRT)
Principles: MaxSPRT is a continuous sequential method that monitors data as it accumulates, comparing observed adverse events to expected counts (based on historical data) using a maximized likelihood ratio. CMaxSPRT extends this by addressing uncertainty in baseline rates with historical matched data.
Strengths: Both enable near real-time detection of safety signals, making them ideal for early identification of issues after new vaccines are introduced.
Limitations: They use a time-invariant detection boundary and have limited ability to adjust for complex confounding, which hinders detailed causal analysis.
Group Sequential Analysis
Principles: This method analyzes data at discrete intervals, comparing post-vaccination adverse event rates to a pre-specified reference level. It uses pre-set stopping rules to control false positives.
Strengths: Allows early termination of surveillance if a safety signal is clear, adapting clinical trial techniques for observational studies.
Limitations: Less efficient than continuous methods for rapid detection and struggles with variations in reference risks, seasonality, and complex time-varying confounders.
TreeScan
Principles: A data-mining tool that scans for unusual temporal clusters of adverse events across many outcome categories, comparing observed vs. expected frequencies in various risk windows.
Strengths: Analyzes a wide range of potential adverse events and adjusts for multiple testing to reduce false positives.
Limitations: Limited in establishing causality or addressing confounding, relying on external methods (e.g., matching) that may not fully capture real-world complexities.
Overall Assessment
The VSD’s methodologies—MaxSPRT/CMaxSPRT, group sequential analysis, and TreeScan—are effective for timely signal detection. However, all face challenges in handling confounding, a critical factor for establishing causal links between vaccines and adverse events, highlighting the need for advanced approaches like federated causal inference.
VSD Data Module Limitations
Dynamic Membership and Tracking Challenges: VSD relies on data from managed care organizations (MCOs) where enrollment changes over time. This complicates longitudinal studies, as individuals may leave the system, disrupting continuity.
Databases Designed for Clinical Care, Not Research: The electronic health records (EHRs) used by VSD were originally created for administrative and clinical purposes, leading to inconsistencies in data formats and coding practices across sites. This requires extensive standardization and validation for research use.
Confidentiality and Data Access Constraints: Privacy protections limit data sharing. External researchers must access de-identified datasets through secure facilities like the National Center for Health Statistics (NCHS) Research Data Center, and even then, they cannot access raw data or recent records (post-2001).
Population Representativeness: While VSD now includes 13 sites, coverage remains uneven. Early sites were concentrated on the West Coast (e.g., Kaiser Permanente in California), skewing demographics toward middle-class, urban populations. Some states remain underrepresented.
Limited Unvaccinated Controls: High vaccination rates in participating MCOs reduce the availability of unvaccinated comparison groups. VSD often uses self-controlled case series or risk interval analyses, which compare postvaccination periods to baseline health data.
Challenges with Delayed or Subtle Adverse Events: Rapid Cycle Analysis (RCA), VSD’s near-real-time surveillance method, focuses on acute events (e.g., febrile seizures). Chronic or delayed conditions (e.g., neurodevelopmental disorders) require longitudinal studies, which are resource-intensive and less definitive.
Underreporting of Non-Severe Events: Events like mild fevers or parental reports via phone calls may not be captured in EHRs unless documented in clinical notes. VSD has experimented with natural language processing (NLP) to extract such data, but this remains labor-intensive.
Limited Power for Rare Events: While VSD monitors ~9 million individuals annually, extremely rare events (e.g., Guillain-Barré Syndrome at 1 per million) require supplementary systems like VAERS or collaborations with larger networks (e.g., FDA Sentinel).
Methodological Limitations: Confounding factors (e.g., pre-existing conditions) and biases (e.g., healthcare-seeking behavior) can affect study outcomes. VSD uses advanced statistical methods like MaxSPRT to reduce false positives, but causality determinations often require additional evidence.
Resource Intensity: Maintaining VSD’s infrastructure, including data standardization, multi-site collaboration, and rapid analysis, demands significant funding and coordination.
Dependence on Diagnostic Codes: EHRs often use non-specific ICD codes, which may inaccurately represent conditions (e.g., "adverse event of medical care"). Manual chart reviews are needed to validate diagnoses, increasing time and costs.
Data Sharing Restrictions: External researchers face barriers:
Reanalyses of published studies require approval from all participating MCOs’ IRBs, which can be inconsistent or denied.
Access is limited to finalized datasets from past studies, preventing exploratory analyses or novel hypotheses testing.
Technological and Workflow Challenges: Integrating new data sources (e.g., pregnancy platforms, infant records) requires complex algorithms and continuous updates, which may lag behind clinical practice changes.
Incomplete Capture of Non-Automated Data: Lab results, imaging reports (e.g., X-rays), or specialist notes not integrated into EHRs may be missed, requiring supplemental data collection.
Current VSD Member Healthcare Organization

The organization below are taking part of VSD:
Acumen, Burlingame, California
Kaiser Permanente Northern California, Oakland, California
Kaiser Permanente Southern California, Los Angeles, California
Denver Health, Denver, Colorado
Kaiser Permanente Colorado, Denver, Colorado
Indiana University, Indianapolis, Indiana*
Harvard Pilgrim Health Care Institute, Boston, Massachusetts
Kaiser Permanente Mid-Atlantic States, Rockville, Maryland
HealthPartners Institute, Minneapolis, Minnesota
Kaiser Permanente Northwest, Portland, Oregon
Kaiser Permanente Washington, Seattle, Washington
Marshfield Clinic Research Institute, Marshfield, Wisconsin
OCHIN, Portland, Oregon*
VSD and Federal Funding
Between the years 2012 to 2022, a total of $150.7M were contractually paid as part of the VACCINE SAFETY DATALINK (VSD) PROJECT (2012-N-14282). Since 2022, another $80.2M in contracts has been assigned via the Vaccine Safety Datalink (VSD) 2022, with a total potential award of $100.6M.
The majority of the money paid between 2012 to 2022 was to the Kaiser Permanente system, a leading nonprofit integrated managed care consortium in the United States, mainly to two entities within it:
Kaiser Foundation Health Plan of Washington (KFHP-WA) is a nonprofit health plan that provides health insurance coverage to members in Washington state, which serves approximately 710,000 members (as of recent estimates) through various plans, including employer-sponsored, individual, Medicare, and Medicaid coverage. It received $120.1M in 2013 for a 7 years contract for the VSD contract.
Kaiser Foundation Hospitals (KFH) is a nonprofit entity that owns and operates the hospital facilities and medical office infrastructure for Kaiser Permanente across eight states (California, Colorado, Georgia, Hawaii, Maryland, Oregon, Virginia, Washington) and the District of Columbia. It serves around 13 Million people, and received
For the 2022 onwards, most of the contracts were due to the COVID19 related research using VSD, with 80% of the contracts going to Kaiser Foundation Hospitals, Harvard Pilgrim Health Care 6%, Health partners Institute 4.3% and so on.
Ethical Oversight and Regulatory Compliance
Regulatory Standards:
HIPAA Compliance: All VSD studies comply with the Health Insurance Portability and Accountability Act (HIPAA), which mandates strict safeguards for protecting participants’ personal health information.
IRB Approvals: Every VSD study must be approved by both the CDC Institutional Review Board (IRB) and the local IRB at each participating MCO site. This dual oversight ensures that ethical standards are uniformly applied across all locations.
Research Protocol Submission for CDC Researchers
CDC researchers are required to submit detailed research protocols to the CDC IRB for ethical review. These protocols outline the study’s objectives, methods, and safeguards for participant protection.
Additionally, approval must be obtained from the IRB of every participating MCO site. This multi-layered review process ensures that the study design and execution meet rigorous ethical standards and respect the rights and privacy of participants across diverse settings.
Study Proposal Development:
For each VSD study, a collaborative team of VSD investigators—comprising experts from multiple MCOs and the CDC—develops a comprehensive study proposal. This proposal includes:
A clear hypothesis to be tested.
A detailed study design, specifying the population, data sources, and methods.
An analytical plan, outlining statistical approaches to evaluate the data.
A rigorous review of the medical outcomes under investigation, ensuring their relevance and measurability.
The proposal is presented to and reviewed by members of the VSD project team, who assess its scientific merit and feasibility. This peer-review-like process enhances the study’s quality and reduces the risk of methodological flaws.
Ethical and Privacy Safeguards:
All VSD studies must adhere to both IRB requirements and HIPAA regulations, ensuring ethical conduct and robust data protection.
Data Minimization: Study-specific analytical data files are created using computerized data, often enriched with additional medical records or other relevant sources. These files include only a small, necessary subset of the entire VSD dataset, minimizing the exposure of sensitive participant information and reducing privacy risks.
Past Research Which Used VSD
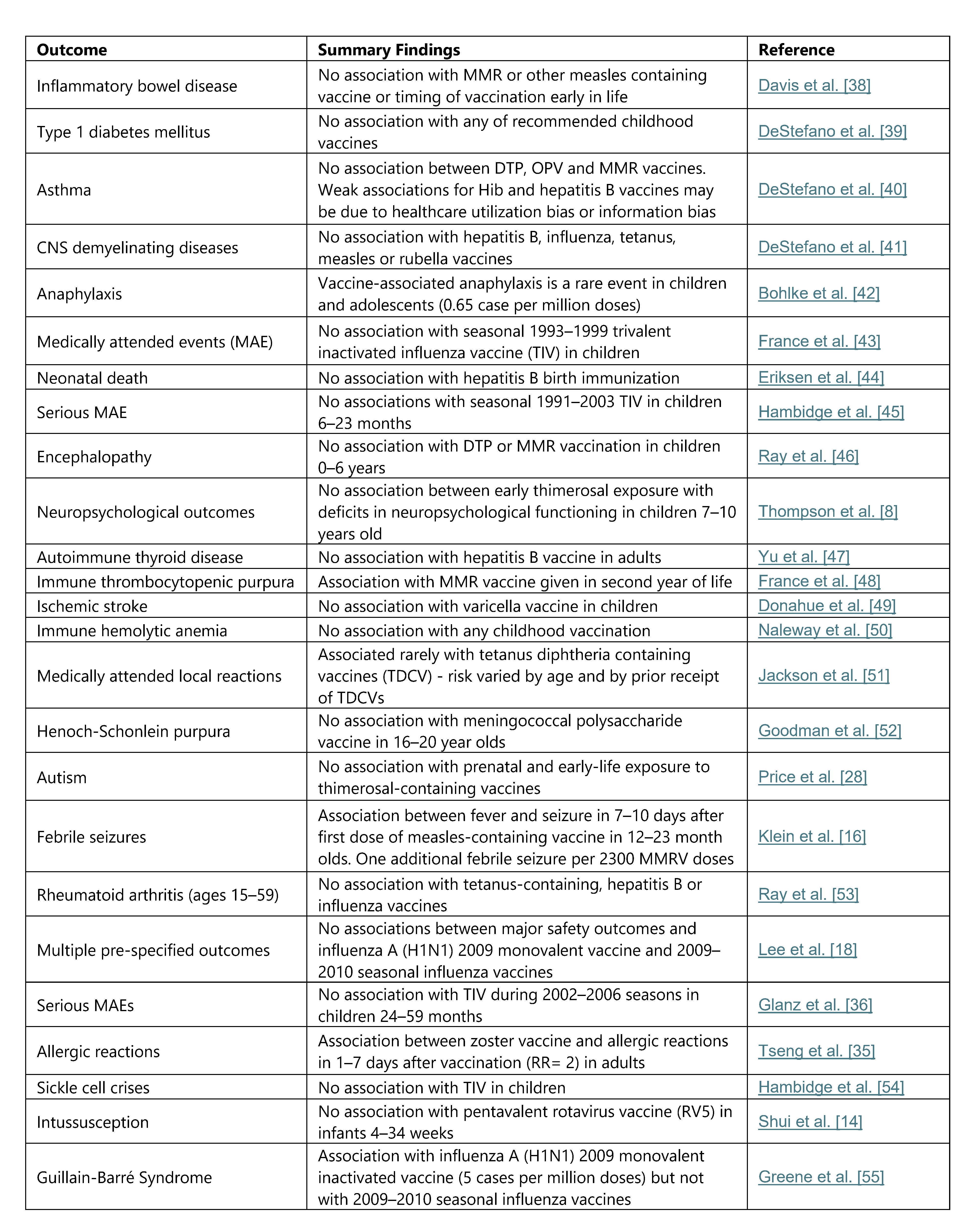
Records Management
As a federal agency, the CDC’s is required to follow the requirement set forth by the National Archives and Records Administration – NARA.
Past NARA Schedule
The management of VSD records was first defined in NARA schedule N1-442-97-001, a Records Control Schedule covering the unscheduled records of the National Immunization Program (NIP). This record was received in NARA on the 16/10/1996, and was focused on the National Immunization Program:
“NATIONAL IMMUNIZATION PROGRAM Provides national leadership for the planning, corotation, and conduct of Federal, State, and local immunization activities In carrying out this mission, the National Immunization Program (I) provides consultation, training, statistical, promotional, educational, epidemiological, and other technical services to assist and stimulate State and local health departments in the planning, development, implementation, and overall improvement of programs for the prevention, control, and eventual eradication of designated serious diseases for which effective immunizing agents are available, (2) supports the establishment of vaccine supply contracts for vaccine distribution to state and local immunization programs, (3) assists state and local health departments m developing and help parents and providers assure that all children are immunized at the appropriate age, assess immunization levels at state and local levels, and monitoring the safety and efficacy of vaccines by linking vaccine administration information with adverse event reporting and disease outbreak patterns, (4) administers preventable diseases, (5) supports a nationwide framework for effective surveillance of designated diseases for which effective immunizing agents are available, (6) supervises state and local assignees working on immunization activities (Approved 10/23/93)”
Item #6 in the list described the record management of VSD
“6 LLDB (Large Link Data Base):
Vaccine safety data link project is designed to identify vaccine adverse events that may occur with the administration of selected immunization for children up to six years of age who use MCOs for primary health care
a. Input:
file received electrically from the West Coast, state birth files from Oregon, California, and Washington, and the data from the 1990 Census files
Authorized Disposition
Delete when data have been entered into the master file or database and verified, or when no longer required to support reconstruction of, or serve as backup to, a master file or database, whichever is later.
b. Master Files: Contains enrollment dates of children up to 6 years of age at four MCOs on the West Coast, vaccines administered to children, outcomes (ICD-9 codes) from hospitals, emergency rooms, and some clinic settings, selected ancillary data, and selected demographic and socio-economic estimates
Authorized Disposition
PERMANENT: Transfer one copy of each final data set to NARA upon completion of study
(Note Data will be formatted in accordance with regulations noted m 3 6 CFR 1228 188, Transfer of Machme-Readable Records to NARA)
The authorization of item #6 was defined in NARA schedule N1-442-97-001 as “disposition pending with NARA”.
The schedule of the Vaccine safety data link have been superseded by new NARA approved records schedule. As the current NARA document explains: “As of: 7/31/2023, Items 6 is superseded by N1442-09-001 Bucket 1”.
Current NARA schedule
N1-442-09-001, which was received in NARA on 9/25/09, is the CDC’s Scientific and Research Project Records. The purpose of N1-442-09-001 was to streamline the NARA record management requirement with regards to all scientific and research project records.
The item described above, “LLDB (Large Link Data Base)”, falls under item #1, “Precedent-Setting Scientific and Research Project Records”. Here is the item:
1. Precedent-Setting Scientific and Research Project Records
These records represent scientific data and all other aspects of mission-related research such as disease prevention and control, environmental health monitoring and health promotion and education. Activities may include project development, demonstration, distribution, assessment, and testing. These records document the planning, history, results, and outcome of a scientific and or research project conducted as part of CDC's mission.
These records may include planning documents and documents that evaluate or appraise a project or other research during its project life. These records may also include original observations, laboratory notebooks, and databases that contain scientific observations, modelling and sampling methodologies, and any other research-related documentation.
Long-Term ongoing Studies That Contain Cumulative Research Data
Authorized Disposition: PERMANENT: Transfer a copy of data to NARA in 1 year intervals (or other time period established with NARA); the first transfer to occur within the first year after the approval of Records Control Schedule. electronic media will be transferred to NARA formatted in accordance with current applicable regulations regarding transfer of electronic records.
Completed Studies
Authorized Disposition: PERMANENT: Transfer to NARA a copy of the completed database no longer than one year after the end of the project Electronic media will be transferred to NARA formatted in accordance with current applicable regulations regarding transfer of electronic records.
Bucket 1 (a table with a list of all the systems which were submitted) includes in it the following item:
Bucket 1 includes in it the following record in bucket 1
System Name: LLDB Large Link Data Base
Formal Name
Previous CDC, RSC: CDC, RSC, 46-4
# Old SF-115: N1-442-97-1, item 6
Previous Retention: Master Files Contains Permanent enrollment dates of children up to 6 years of age at four HMO=s on the West Coast, vaccines administered to children outcomes (ICD-9 codes) from hospitals, emergency rooms, and some…
Proposed Retention: PERMANENT
Research data and NARA requirements
Research papers might be included as part of the "research-related documentation," but the explicit mention of "data" and "database" indicates that the primary requirement is the transfer of the data used to produce the research results. This means that from a federal record management perspective, all the research which is mentioned before should have submitted all the data that was used to reach the research paper to NARA. Also, the database which was used up until 2001 to aggregate all the information that was used for research even after the VSD moved
NARA Evaluation
In 2019 the National Archives and Records Administration (NARA) has conducted an evaluation of the CDC's records management practices, particularly for research projects. It found 3 findings:
Inconsistent implementation of records lifecycle governance, with limited interaction between Subject Records Liaisons (SRLs), Records Liaisons (RLs), and research project staff. Some inventories were outdated (e.g., one since 2011) or missing (e.g., a study active since 2001 without a files inventory). Confusion existed over applying schedule dispositions to records outside data management systems.
Research project staff were not creating Data Management Plans (DMPs) as required by CDC operational policy (CDC-GA-2005-14, effective January 26, 2016, with a deadline of January 26, 2019, for existing projects). Only one project reviewed had a DMP, which lacked records management (RM) elements and was not reviewed by the assigned SRL.
The CDC was not conducting records management evaluations of its Centers, Institutes, and Offices (CIOs), despite requirements under 36 CFR 1220.34(j), HHS-2015-0004.002, and CDCGA-2005-07. The RM strategic priorities plan (dated December 4, 2018) included a goal to audit five CIOs annually, but no evaluations were conducted.
Recommendations include ensuring all records are properly inventoried and scheduled, developing policies to include records management in DMPs, and creating an evaluation program for CIO compliance.
Additional observations noted ongoing efforts to update records schedules and email management practices, with NARA inspecting four longitudinal projects, three scheduled as permanent, with records transferred as planned. The CDC was required to submit a corrective action plan to NARA within 60 days.
Data Ownership and Anonymization
Data Ownership
Kaiser Permanente sites, Harvard Pilgrim, HealthPartners, Marshfield Clinic, Denver Health, Indiana University, OCHIN, Acumen share a Limited Data Set with CDC (a public health authority) under a Data Use Agreement.
Under HIPAA, the Health Care Organization (HCO), they are the covered entities, which means they are organizations who are subject to HIPAA regulations because they handle protected health information (PHI). While the The CDC is permitted to receive PHI for public health surveillance, each entity retains control over its PHI prior to transfer.
Prior to 2001, while the CDC was recieving datasets from the HCOs, the ability of the CDC to use the data was govern by the Data Usage Agreement which was signed with the CDC. It is my understanding that due to HIPPA, it is most likely that the HCOs has retained the ability to decide what research would be conducted on the data.
The implications of the DUA meant that
Prior to 2001, due to HIPPA driven DUA, the CDC have a dataset but is unable to provide it without recieving an approval from the the HCOs.
After 2001, when data was no longer sent to the CDC, and all attempts to conduct research on it requires
Anonymization
For a dataset to be considered as anonymized and HIPAA compliant, de-identified data must have 18 specific identifiers removed, as outlined in the HIPAA Privacy Rule (45 CFR 164.514(b)(2)). This is known as the Safe Harbor method for de-identification, ensuring the data is no longer considered Protected Health Information (PHI).
Below is the list of the 18 identifiers that must be removed:
· Geographic subdivisions smaller than a state (e.g., street address, city, county, precinct, ZIP code, or their equivalent geocodes, except for the first three digits of a ZIP code if the geographic unit formed by combining all ZIP codes with the same three initial digits contains more than 20,000 people).
· All elements of dates (except year) related to an individual, including birth date, admission date, discharge date, date of death, or age if over 89 (unless aggregated into a single category of age 90 or older).
Telephone numbers.
Fax numbers.
Email addresses.
Social Security numbers.
Medical record numbers.
Health plan beneficiary numbers.
Account numbers.
Certificate/license numbers (e.g., driver’s license, professional licenses).
Vehicle identifiers and serial numbers, including license plate numbers.
Device identifiers and serial numbers (e.g., for medical devices).
Web Universal Resource Locators (URLs).
Internet Protocol (IP) addresses.
Biometric identifiers, including fingerprints, voiceprints, and retina scans.
Full-face photographic images and any comparable images.
Any other unique identifying number, characteristic, or code (unless it is re-coded to prevent re-identification and is not derived from or related to other identifiers).
The VSD dataset IS NOT fully anonymized under HIPAA’s Safe Harbor or Expert Determination methods, which means this data is a protected health information (PHI) because:
The VSD dataset contains Geographic subdivisions smaller than a state - census tract. This is a fine-grained geography data that describes a small areas, typically with 1,200–8,000 people (optimally 4000 people), used for detailed geographic analysis.
The VSD's dataset contain full date information necessary for its surveillance activities, which means that it is not anonymized as it contains HIPPA's protected health information (PHI).
The pseudonyms (VSD unique ID) done in VSD DO NOT eliminate linkage risk if an adversary holds auxiliary data (e.g., local immunization logs).
One might claim that if someone undergone a rare procedure, even if it only been identified using a code, might constituted the identification of an individual, which violates the last point (Any other unique identifying number, characteristic, or code (unless it is re-coded to prevent re-identification and is not derived from or related to other identifiers).
The Combinations of birth date + census tract + vaccination dates + rare procedures can uniquely pinpoint individuals, especially in sparsely populated tracts. It also does not eliminates risks associated with the use of auxiliary data.
While HIPAA permits a “limited data set” to include dates and geographic subdivisions up to ZIP code, city, state, and even by some interpretations census tract if covered by a DUA, this is still PHI, not de‐identified data.
Privacy Implications
The CDC CANNOT make the data in the Vaccine Safety Datalink (VSD) public because:
They don't control the data and/or not allowed to release it due to DUA.
Release of the data will violate HIPPA.
HOWEVER, THERE IS A WAY to perform research on VSD in a HIPPA compliant way, but that is a topic for a completely different article.
Looking forward to your comments and thoughts
Love,
Ehden